Pandas DataFrame를 csv로 저장하고 로드하기
Pandas DataFrame에 저장된 데이터셋을 파일로 저장하고 로드하면 좋겠다는 생각이 들어서 여러모로 검색을
하여서 조금씩 정보를 찾았다.
일단 csv로 저장하는 방법이다. 매우 간단하다.
import pandas as pd
time_pd = pd.DataFrame(0., columns=col, index=time_range)
time_pd.to_csv("filename.csv", mode='w')일단 위의 소스는 time_pd라는 임의의 DataFrame을 생성한 뒤 바로 csv파일로 저장하는 소스코드이다.
mode에 인자값을 ‘a’ 로 해주면 덮어쓰기가 아닌 추가로 내용을 쓸 수 있다.
time_pd2.to_csv("filename.csv", mode='a', header=False)이렇게 하면 위에서 말한대로 추가가 되고 header를 False 값을 주면 추가되는 값에 header가 찍히지 않는다.
dataset = pd.read_csv("filename.csv", index_col=0)
print(dataset)반대로 csv파일을 불러오는 소스코드이다. 인덱스 column을 0번째 줄로 정하겠다는 의미이다.
참으로 유용하면서 간단한 모듈이라고 할 수 있겠다.
'Python' 카테고리의 다른 글
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
|---|---|
| Flask socketIO simple usage and code (0) | 2018.02.14 |
| python multiprocessing 사용하기 (1) | 2018.02.12 |
| python BeautifulSoup 이용한 간단한 크롤링 (0) | 2017.11.12 |
| Anaconda Python package tool kit 간단한 사용법 (0) | 2017.11.08 |
python BeautifulSoup 이용한 간단한 크롤링
Python 모듈 중에서는 유명한 웹 파싱 모듈이 많이 있다.
이 포스팅에서는 그 중에 하나인 BeautifulSoup를 이용한 간단한 크롤링을 해보고자 한다.
이유는 나중에 잊어버릴 것 같다;;
먼저 자신의 파이썬 환경에 BeautifulSoup4를 설치해 준다.
pip install beautifulsoup4 등 여러가지 방법으로 자신의 환경에 설치를 한 뒤에
from bs4 import BeautifulSoup from urllib.request import urlopen
설치한 모듈을 임포트 한다. 아래 웹요청 내장 모듈도 임포트 한다.
이번에 간단하게 크롤링할 내용은 네이버 실시간 검색어이다.
base_url = "http://www.naver.com/"
db = pymysql.connect("localhost","root","123456","realtimekeyword", charset='utf8')
cursor = db.cursor()크롤링만 하면 심심해서 나는 mysql db에 크롤링한 내용을 저장해 보았다.
url에 네이버 홈 url을 저장한 뒤 pymysql 모듈로 로컬에 접속을 cursor에 저장하였다.
이 후에 본격적으로 파싱 코드를 작성하였다.
data = urlopen(base_url).read()
soup = BeautifulSoup(data, "html.parser")
total_data = str(soup.find_all(attrs={'class': 'ah_l'}))
datalist = total_data.split('<li class=')네이버url을 요청한 뒤 beautifulsoup를 통해 파싱한 정보를 soup에 저장한 뒤
soup에 저장된 데이터에서 class타입이 ‘ah_l’인 모든 정보를 찾아서 total_data에 저장하였다.
그리고 그 하위의 ‘<li class=’로 된 정보를 스플릿하여 datalist라는 리스트에 저장하였다.
이 과정에서 리스트에는 각 실검 단어들이 리스트 하나하나에 들어가게 된다.

현재 기준의 네이버의 페이지 코드이다. 이것을 참고하면서 파싱하면 된다.
전체 코드는 이러하다.
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from urllib.request import urlopen
from datetime import datetime, timedelta
import time
import pymysql
from traceback import format_exc
base_url = "http://www.naver.com/"
db = pymysql.connect("localhost","root","123456","realtimekeyword", charset='utf8')
cursor = db.cursor()
def collecting(base_url):
while True:
data = urlopen(base_url).read()
soup = BeautifulSoup(data, "html.parser")
total_data = str(soup.find_all(attrs={'class': 'ah_l'}))
datalist = total_data.split('<li class=')
data = []
nowtime = datetime.utcnow() + timedelta(hours=9)
for each in datalist[1:]:
try:
RRank = int(each.split('class="ah_r">')[1].split('</span>')[0])
tit = str(each.split('class="ah_k">')[1].split('</span>')[0])
rk = int(each.split('class="ah_r">')[1].split('</span>')[0])
data.append((RRank, tit, rk, str(nowtime)))
except IndexError:
print(format_exc())
query = """insert into keywords(rtrank, title, rank, recordtime) values (%s, %s, %s, %s)"""
cursor.executemany(query, tuple(data))
db.commit()
time.sleep(300)
collecting(base_url)좀 허접하지만 연습 정도는 충분히 된다.
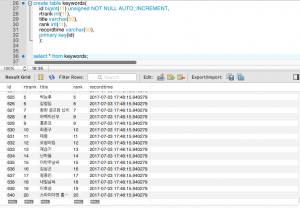
디비에는 이러한 식으로 저장이 된다.
'Python' 카테고리의 다른 글
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
|---|---|
| Flask socketIO simple usage and code (0) | 2018.02.14 |
| python multiprocessing 사용하기 (1) | 2018.02.12 |
| Pandas DataFrame를 csv로 저장하고 로드하기 (0) | 2017.11.12 |
| Anaconda Python package tool kit 간단한 사용법 (0) | 2017.11.08 |

