실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기
안녕하세요 뜨거운 여름동안 잘 쉬다가 오랜만에 포스팅을 하게 되었습니다.
이번에는 제가 개인적으로 진행하고 있는 프로젝트의 소스와 내용을 포스팅하게 되었습니다.
그 내용은 제목에 있습니다. 자세히 표현하자면 네이버 뉴스를 1시간마다 크롤링하여
크롤링한 뉴스의 내용을 엘라스틱 서치라는 검색엔진 API로 뿌려주는 겁니다.
일단 사전에 환경이 준비되어 있어야 합니다. 그 환경은 아래에 기재하였습니다.
- 엘라스틱서치를 설치하고 실행까지 해주셔야 합니다.
- Beautifulsoup와 pandas와 같은 파이썬 패키지를 설치해 주셔야 합니다.
- REST API로 api를 구현하되 원하는 프레임워크 및 라이브러리로 구현을 해주시면 됩니다.(저는 nodeJS의 Express로 구현 하였습니다.)
- 위의 내용들은 저의 환경이니 각자 원하시는 환경으로 커스터마이징 하셔도 됩니다.
일단 뉴스 내용을 수집해야 하니 크롤러부터 들어갑니다.
바로 소스코드 공개합니다.
realtime.py
#-*- coding: utf-8 -*-
import os
import sys
from bs4 import BeautifulSoup
from urllib.request import urlopen
from datetime import datetime, timedelta
from traceback import format_exc
dir = os.path.dirname(__file__)
sys.path.insert(0, os.path.join(dir, '../save'))
import pandas_csv
import to_es
base_url = "http://news.naver.com/#"
def collecting(base_url):
data = urlopen(base_url).read()
soup = BeautifulSoup(data, "html.parser")
total_data = soup.find_all(attrs={'class': 'main_component droppable'})
colect_time = str(datetime.utcnow().replace(microsecond=0) + timedelta(hours=9))[:16]
for each_data in total_data:
category = ""
try:
category = str(each_data.find_all(attrs={'class': 'tit_sec'})).split('>')[2][:-3]
except:
pass
data = str(each_data.find_all(attrs={'class': 'mlist2 no_bg'}))
news_list = data.split('<li>')
for each_news in news_list[1:]:
news_block = each_news.split('href="')[1]
# print(news_block)
title = news_block.split('<strong>')[1].split('</strong>')[0]
# print(title)
news_url = news_block.split('"')[0].replace("amp;", "")
# print(news_url)
soup2 = BeautifulSoup(urlopen(news_url).read(), "html.parser")
# print(soup2)
# article_info = soup2.find_all(attrs={'class': 'article_info'})
# print(article_info)
article_body = str(soup2.find_all(attrs={'id': 'articleBodyContents'}))
insert_data = {"source": "naver_news",
"category": category,
"title": title,
"article_body": article_body,
"colect_time": colect_time}
pandas_csv.to_csv(insert_data)
to_es.to_elastic(insert_data)
collecting(base_url)위의 realtime.py는 한번 실행시키면 네이버 뉴스의 여러 카테고리의 뉴스들을 좌악~ 크롤링해 옵니다.
그리고 가져온 내용들은 for문을 돌며 각 뉴스 기사 단위로 insert_data라는 딕셔너리에 저장이 됩니다.
저는 이 딕셔너리를 csv와 elastic search 에 저장을 하게 코드를 짜 놓았습니다.
엘라스틱서치에 저장하는 소스코드는
pandas_csv.py
import os
import pandas as pd
from datetime import datetime, timedelta
import configparser
import glob
config = configparser.ConfigParser()
config.read('/home/yutw/project/searchnews/crawler/crawler.conf')
def to_csv(data):
pathlink ="/home/yutw/data/searchnews"
# db create
if not os.path.isdir(pathlink):
os.mkdir(pathlink)
present_date = str(datetime.utcnow() + timedelta(hours=9))[:10]
# col = ["source", "category", "title", "article_body", "colect_time"]
if len(glob.glob(pathlink + "/" + present_date + ".csv")) == 1:
cnt = len(pd.read_csv(pathlink + "/" + present_date + ".csv", index_col=0).index)
time_pd = pd.DataFrame(data, index=[cnt])
time_pd.to_csv(pathlink + "/" + present_date + ".csv", mode='a', header=False)
else:
cnt = 0
time_pd = pd.DataFrame(data, index=[cnt])
time_pd.to_csv(pathlink + "/" + present_date + ".csv", mode='a')
요 위까지 csv로 내용을 저장해 줍니다.
그리고 엘라스틱서치에도 insert를 해줍니다.
to_es.py
from elasticsearch import Elasticsearch
es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
import json
import configparser
from datetime import datetime, timedelta
import pandas as pd
config = configparser.ConfigParser()
config.read('/home/yutw/project/searchnews/crawler/crawler.conf')
def to_elastic(data):
pathlink = "/home/yutw/data/searchnews"
present_date = str(datetime.utcnow() + timedelta(hours=9))[:10]
del_date = str(datetime.utcnow() - timedelta(hours=39))[:10]
cnt = len(pd.read_csv(pathlink + "/" + present_date + ".csv", index_col=0).index)
es.index(index="searchnews", doc_type='naver_news', id=present_date + "-" + str(cnt), body=json.dumps(data))
if cnt == 1:
days = [x for x in range(1, int(del_date[-2:]))]
for day in days:
if len(str(day)) == 1:
for each in range(1, 1500):
try:
es.delete(index="searchnews", doc_type="naver_news", id=del_date[:8] + '0' + str(day) + "-" + str(each))
except:
pass
else:
for each in range(1, 1500):
try:
es.delete(index="searchnews", doc_type="naver_news", id=del_date[:8] + str(day) + "-" + str(each))
except:
pass
이 후에 저장한 내용을 API로 뿌려주면 되는데요.
여기서 저는 Express 의 api를 사용해서 간단하게 API서버를 구현하였습니다.
우선 Express 기본 샘플 프로젝트를 만들어 줍니다.
https://github.com/gothinkster/node-express-realworld-example-app.git
이 곳을 통해 내려받거나 원하는 형태의 소스코드를 받으시고
api쪽(저는 routes의 디렉터리 안에 구성하였습니다.)
index.js
var express = require('express');
var fs = require('fs');
var router = express.Router();
var elasticsearch = require('elasticsearch');
var client = new elasticsearch.Client({
host: 'localhost:9200',
log: 'trace'
});
/* GET home page. */
router.get('/', function(req, res, next) {
res.render('index', { title: 'Express' });
});
router.get('/newsSearch/:keyword', function (req, res) {
client.search({
q: req.params.keyword
}).then(function (body) {
var hits = body.hits.hits;
res.json(hits);
}, function (error) {
console.trace(error.message);
});
});
router.get('/user', function (req, res) {
var value = {"test": "user"};
console.log(value);
res.json(value);
});
module.exports = router;
API 또한 원하는 방향으로 해주시면 됩니다. 위의 소스코드는 keyword에 따라 모두 검색할 수 있게 코드를 작성하였습니다.
이제 API서버도 동작시켜 줍니다.
그러면 모두 완료되었습니다. python realtime.py 를 실행하면 크롤링이 되고 자동으로 엘라스틱서치에도 insert가 되어 api서버에서 keyword를 검색하면 키워드에 맞는 뉴스들이 검색이 됩니다.

이런식으로 request를 보내면

이렇게 json형식으로 response가 떨어집니다. 여기까지 제 방식대로 코딩했는데요. 원하시는 내용을 코드를 편집해서 쓰셔도 됩니다.
여기까지 포스팅을 마칩니다.
'Python' 카테고리의 다른 글
| linux 파일 동기화 소스 auto_sync (0) | 2018.09.09 |
|---|---|
| Python패키지 목록 requirements.txt 관리하기 (0) | 2018.08.08 |
| Python sounddevice를 이용한 소리 탐지 (0) | 2018.04.23 |
| python configparser 사용하기 (0) | 2018.03.28 |
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
Python sounddevice를 이용한 소리 탐지
이번에는 microphone과 python의 sounddevice 라이브러리를 이용한 소리 탐지 소스를 만들어 보았습니다.
우선 설치부터 해야지요~
운영체제마다 조금씩 다르지만 맥기준으로 설명하겠습니다.
우선 sounddevice를 microphone과 연결하기 위한 portaudio를 설치해줍니다.
brew install portaudio 명령을 통해 설치를 해줍니다.
그리고 자신의 파이썬 환경에 sounddevice설치를 위해 pip install sounddevice 를 통해 라이브러리를 설치해줍니다.
이제 제가 간단히 테스트해본 코드를 봅시다.
우선 필요한 라이브러리들을 임포트해줍니다.
import time import sounddevice as sd import numpy as np
그리고 몇 초단위로 코드를 진행할 것인지 duration을 정해줍니다.
duration = 3 # seconds
저는 3초로 했습니다.
while True:
present_wave = []
compare_wave = []
def print_sound(indata, outdata, frames, time, status):
volume_norm = np.linalg.norm(indata)*10
print("|" * int(volume_norm))
with sd.Stream(callback=print_sound):
sd.sleep(duration * 1000)그리고 반복문으로 반복해줍니다.
이렇게 하면
마이크로폰으로 들어오는 input stream을 파이프 기호로 표시해줍니다.

이런식으로 말이죠
여기에 여러분이 원하는 기능을 추가할 수 있습니다.
저는 3초동안 불규칙한 웨이브가 감지되면 udp 소켓으로 데이터를 보내도록 코드를 만들었습니다.
아래는 전체코드입니다.
# Print out realtime audio volume as ascii bars
import time
import sounddevice as sd
import numpy as np
import copy
import socket
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
cli = ("127.0.0.1", 9999)
data = b'True'
error_wave = ''
gijunjum = 1000
duration = 3 # seconds
prev_wave = []
init = True
while True:
present_wave = []
compare_wave = []
def print_sound(indata, outdata, frames, time, status):
volume_norm = np.linalg.norm(indata)*10
print("|" * int(volume_norm))
present_wave.append(gijunjum - volume_norm)
with sd.Stream(callback=print_sound):
sd.sleep(duration * 1000)
if init is True:
prev_wave = copy.copy(present_wave)
init = False
try:
for idx, each in enumerate(present_wave):
compare_wave.append(each - prev_wave[idx])
except IndexError:
pass
temp = 0
total_change = 0
for cw in compare_wave:
if abs(cw - temp) > 4:
total_change = total_change + 1
temp = cw
if total_change > 30:
print("sound detect!!")
client_socket.sendto(data, cli)
time.sleep(0.01)여기까지 마치겠습니다. 끝~!
'Python' 카테고리의 다른 글
| Python패키지 목록 requirements.txt 관리하기 (0) | 2018.08.08 |
|---|---|
| 실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기 (1) | 2018.08.07 |
| python configparser 사용하기 (0) | 2018.03.28 |
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
| Flask socketIO simple usage and code (0) | 2018.02.14 |
MacOS 에서 SIP(System Integrity Protection status) 해제하기
이번에는 맥의 시스템 파일을 건드리지 않으면 좋겠지만
필요에 의해서 건드려야 할 때 시스템 무결성을 지켜주는 보호 시스템인
SIP(System Integrity Protection status)를 간단하게 해제하는 방법을 알아보겠습니다.
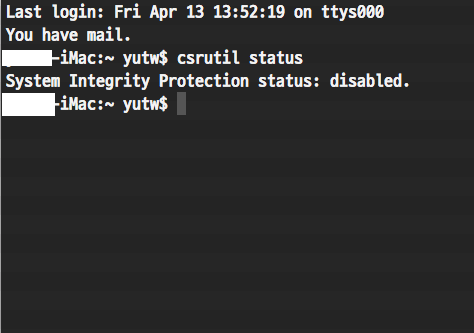
우선 위의 스크린샷은 제 맥의 SIP를 disable 시킨 상태의 모습입니다.
일단 맥의 기본 부팅 상태에서는 SIP를 해제할 수 없습니다.
재부팅을 하면서 맥의 복구모드로 진입하셔야 합니다.
맥의 사과 화면이 나오기 전에 맥이 켜지는 시점에 command + R 키를 눌러 복구모드로 진입한 뒤에
유틸리티 메뉴에서 터미널을 열어
csrutil disable
라고 입력해 줍니다.
그리고 재부팅을 해줍니다.
SIP가 비활성화 됐는지 확인하고 싶으면 csrutil status 명령어로 확인하여 위 스크린샷처럼 disabled가 나오면
완료 된 것 입니다. 끝!
'Mac' 카테고리의 다른 글
| 맥북 egpu 연동(nvidia) (0) | 2019.06.10 |
|---|---|
| MeCab 및 mecab-python 설치하기(MacOS) (0) | 2019.02.06 |
