Python패키지 목록 requirements.txt 관리하기
안녕하세요 이번에는 Python의 패키지 환경을 쉽게 관리할 수 있도록 도와주는
requirements.txt 을 간단하게 소개하고자 합니다.
파이썬을 쓰면서 가끔 불편한 것이 새로운 환경에 자신이 설치하고자 하는 파이썬 패키지를
일일히 구성해주는 일이 불편할텐데요.
그것을 쉽게 관리해주는 것이 바로 requirements.txt 입니다.
우선 자신이 구성한 환경을 requirements.txt 로 만드는 명령어는
pip freeze > requirements.txt
입니다.
그러면 설치되있는 패키지들이 알파벳순으로 requirements.txt 로 저장이 됩니다.
그리고 이 requirements.txt 를 반대로 지정한 환경에 설치하는 방법은
pip install -r requirements.txt
입니다.
이 명령어로 설치가 안되는 패키지도 있습니다.
다른 패키지에 대한 의존성이라든지 여러가지 요소로 설치가 안되는 패키지는 수동으로 설치를 해주시면 됩니다.
이 것으로 requirements.txt 에 대해 마치겠습니다~~
'Python' 카테고리의 다른 글
| python socket(tcp, udp) 사용하기 (0) | 2018.12.02 |
|---|---|
| linux 파일 동기화 소스 auto_sync (0) | 2018.09.09 |
| 실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기 (1) | 2018.08.07 |
| Python sounddevice를 이용한 소리 탐지 (0) | 2018.04.23 |
| python configparser 사용하기 (0) | 2018.03.28 |
실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기
안녕하세요 뜨거운 여름동안 잘 쉬다가 오랜만에 포스팅을 하게 되었습니다.
이번에는 제가 개인적으로 진행하고 있는 프로젝트의 소스와 내용을 포스팅하게 되었습니다.
그 내용은 제목에 있습니다. 자세히 표현하자면 네이버 뉴스를 1시간마다 크롤링하여
크롤링한 뉴스의 내용을 엘라스틱 서치라는 검색엔진 API로 뿌려주는 겁니다.
일단 사전에 환경이 준비되어 있어야 합니다. 그 환경은 아래에 기재하였습니다.
- 엘라스틱서치를 설치하고 실행까지 해주셔야 합니다.
- Beautifulsoup와 pandas와 같은 파이썬 패키지를 설치해 주셔야 합니다.
- REST API로 api를 구현하되 원하는 프레임워크 및 라이브러리로 구현을 해주시면 됩니다.(저는 nodeJS의 Express로 구현 하였습니다.)
- 위의 내용들은 저의 환경이니 각자 원하시는 환경으로 커스터마이징 하셔도 됩니다.
일단 뉴스 내용을 수집해야 하니 크롤러부터 들어갑니다.
바로 소스코드 공개합니다.
realtime.py
#-*- coding: utf-8 -*-
import os
import sys
from bs4 import BeautifulSoup
from urllib.request import urlopen
from datetime import datetime, timedelta
from traceback import format_exc
dir = os.path.dirname(__file__)
sys.path.insert(0, os.path.join(dir, '../save'))
import pandas_csv
import to_es
base_url = "http://news.naver.com/#"
def collecting(base_url):
data = urlopen(base_url).read()
soup = BeautifulSoup(data, "html.parser")
total_data = soup.find_all(attrs={'class': 'main_component droppable'})
colect_time = str(datetime.utcnow().replace(microsecond=0) + timedelta(hours=9))[:16]
for each_data in total_data:
category = ""
try:
category = str(each_data.find_all(attrs={'class': 'tit_sec'})).split('>')[2][:-3]
except:
pass
data = str(each_data.find_all(attrs={'class': 'mlist2 no_bg'}))
news_list = data.split('<li>')
for each_news in news_list[1:]:
news_block = each_news.split('href="')[1]
# print(news_block)
title = news_block.split('<strong>')[1].split('</strong>')[0]
# print(title)
news_url = news_block.split('"')[0].replace("amp;", "")
# print(news_url)
soup2 = BeautifulSoup(urlopen(news_url).read(), "html.parser")
# print(soup2)
# article_info = soup2.find_all(attrs={'class': 'article_info'})
# print(article_info)
article_body = str(soup2.find_all(attrs={'id': 'articleBodyContents'}))
insert_data = {"source": "naver_news",
"category": category,
"title": title,
"article_body": article_body,
"colect_time": colect_time}
pandas_csv.to_csv(insert_data)
to_es.to_elastic(insert_data)
collecting(base_url)위의 realtime.py는 한번 실행시키면 네이버 뉴스의 여러 카테고리의 뉴스들을 좌악~ 크롤링해 옵니다.
그리고 가져온 내용들은 for문을 돌며 각 뉴스 기사 단위로 insert_data라는 딕셔너리에 저장이 됩니다.
저는 이 딕셔너리를 csv와 elastic search 에 저장을 하게 코드를 짜 놓았습니다.
엘라스틱서치에 저장하는 소스코드는
pandas_csv.py
import os
import pandas as pd
from datetime import datetime, timedelta
import configparser
import glob
config = configparser.ConfigParser()
config.read('/home/yutw/project/searchnews/crawler/crawler.conf')
def to_csv(data):
pathlink ="/home/yutw/data/searchnews"
# db create
if not os.path.isdir(pathlink):
os.mkdir(pathlink)
present_date = str(datetime.utcnow() + timedelta(hours=9))[:10]
# col = ["source", "category", "title", "article_body", "colect_time"]
if len(glob.glob(pathlink + "/" + present_date + ".csv")) == 1:
cnt = len(pd.read_csv(pathlink + "/" + present_date + ".csv", index_col=0).index)
time_pd = pd.DataFrame(data, index=[cnt])
time_pd.to_csv(pathlink + "/" + present_date + ".csv", mode='a', header=False)
else:
cnt = 0
time_pd = pd.DataFrame(data, index=[cnt])
time_pd.to_csv(pathlink + "/" + present_date + ".csv", mode='a')
요 위까지 csv로 내용을 저장해 줍니다.
그리고 엘라스틱서치에도 insert를 해줍니다.
to_es.py
from elasticsearch import Elasticsearch
es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
import json
import configparser
from datetime import datetime, timedelta
import pandas as pd
config = configparser.ConfigParser()
config.read('/home/yutw/project/searchnews/crawler/crawler.conf')
def to_elastic(data):
pathlink = "/home/yutw/data/searchnews"
present_date = str(datetime.utcnow() + timedelta(hours=9))[:10]
del_date = str(datetime.utcnow() - timedelta(hours=39))[:10]
cnt = len(pd.read_csv(pathlink + "/" + present_date + ".csv", index_col=0).index)
es.index(index="searchnews", doc_type='naver_news', id=present_date + "-" + str(cnt), body=json.dumps(data))
if cnt == 1:
days = [x for x in range(1, int(del_date[-2:]))]
for day in days:
if len(str(day)) == 1:
for each in range(1, 1500):
try:
es.delete(index="searchnews", doc_type="naver_news", id=del_date[:8] + '0' + str(day) + "-" + str(each))
except:
pass
else:
for each in range(1, 1500):
try:
es.delete(index="searchnews", doc_type="naver_news", id=del_date[:8] + str(day) + "-" + str(each))
except:
pass
이 후에 저장한 내용을 API로 뿌려주면 되는데요.
여기서 저는 Express 의 api를 사용해서 간단하게 API서버를 구현하였습니다.
우선 Express 기본 샘플 프로젝트를 만들어 줍니다.
https://github.com/gothinkster/node-express-realworld-example-app.git
이 곳을 통해 내려받거나 원하는 형태의 소스코드를 받으시고
api쪽(저는 routes의 디렉터리 안에 구성하였습니다.)
index.js
var express = require('express');
var fs = require('fs');
var router = express.Router();
var elasticsearch = require('elasticsearch');
var client = new elasticsearch.Client({
host: 'localhost:9200',
log: 'trace'
});
/* GET home page. */
router.get('/', function(req, res, next) {
res.render('index', { title: 'Express' });
});
router.get('/newsSearch/:keyword', function (req, res) {
client.search({
q: req.params.keyword
}).then(function (body) {
var hits = body.hits.hits;
res.json(hits);
}, function (error) {
console.trace(error.message);
});
});
router.get('/user', function (req, res) {
var value = {"test": "user"};
console.log(value);
res.json(value);
});
module.exports = router;
API 또한 원하는 방향으로 해주시면 됩니다. 위의 소스코드는 keyword에 따라 모두 검색할 수 있게 코드를 작성하였습니다.
이제 API서버도 동작시켜 줍니다.
그러면 모두 완료되었습니다. python realtime.py 를 실행하면 크롤링이 되고 자동으로 엘라스틱서치에도 insert가 되어 api서버에서 keyword를 검색하면 키워드에 맞는 뉴스들이 검색이 됩니다.

이런식으로 request를 보내면

이렇게 json형식으로 response가 떨어집니다. 여기까지 제 방식대로 코딩했는데요. 원하시는 내용을 코드를 편집해서 쓰셔도 됩니다.
여기까지 포스팅을 마칩니다.
'Python' 카테고리의 다른 글
| linux 파일 동기화 소스 auto_sync (0) | 2018.09.09 |
|---|---|
| Python패키지 목록 requirements.txt 관리하기 (0) | 2018.08.08 |
| Python sounddevice를 이용한 소리 탐지 (0) | 2018.04.23 |
| python configparser 사용하기 (0) | 2018.03.28 |
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
Python sounddevice를 이용한 소리 탐지
이번에는 microphone과 python의 sounddevice 라이브러리를 이용한 소리 탐지 소스를 만들어 보았습니다.
우선 설치부터 해야지요~
운영체제마다 조금씩 다르지만 맥기준으로 설명하겠습니다.
우선 sounddevice를 microphone과 연결하기 위한 portaudio를 설치해줍니다.
brew install portaudio 명령을 통해 설치를 해줍니다.
그리고 자신의 파이썬 환경에 sounddevice설치를 위해 pip install sounddevice 를 통해 라이브러리를 설치해줍니다.
이제 제가 간단히 테스트해본 코드를 봅시다.
우선 필요한 라이브러리들을 임포트해줍니다.
import time import sounddevice as sd import numpy as np
그리고 몇 초단위로 코드를 진행할 것인지 duration을 정해줍니다.
duration = 3 # seconds
저는 3초로 했습니다.
while True:
present_wave = []
compare_wave = []
def print_sound(indata, outdata, frames, time, status):
volume_norm = np.linalg.norm(indata)*10
print("|" * int(volume_norm))
with sd.Stream(callback=print_sound):
sd.sleep(duration * 1000)그리고 반복문으로 반복해줍니다.
이렇게 하면
마이크로폰으로 들어오는 input stream을 파이프 기호로 표시해줍니다.

이런식으로 말이죠
여기에 여러분이 원하는 기능을 추가할 수 있습니다.
저는 3초동안 불규칙한 웨이브가 감지되면 udp 소켓으로 데이터를 보내도록 코드를 만들었습니다.
아래는 전체코드입니다.
# Print out realtime audio volume as ascii bars
import time
import sounddevice as sd
import numpy as np
import copy
import socket
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
cli = ("127.0.0.1", 9999)
data = b'True'
error_wave = ''
gijunjum = 1000
duration = 3 # seconds
prev_wave = []
init = True
while True:
present_wave = []
compare_wave = []
def print_sound(indata, outdata, frames, time, status):
volume_norm = np.linalg.norm(indata)*10
print("|" * int(volume_norm))
present_wave.append(gijunjum - volume_norm)
with sd.Stream(callback=print_sound):
sd.sleep(duration * 1000)
if init is True:
prev_wave = copy.copy(present_wave)
init = False
try:
for idx, each in enumerate(present_wave):
compare_wave.append(each - prev_wave[idx])
except IndexError:
pass
temp = 0
total_change = 0
for cw in compare_wave:
if abs(cw - temp) > 4:
total_change = total_change + 1
temp = cw
if total_change > 30:
print("sound detect!!")
client_socket.sendto(data, cli)
time.sleep(0.01)여기까지 마치겠습니다. 끝~!
'Python' 카테고리의 다른 글
| Python패키지 목록 requirements.txt 관리하기 (0) | 2018.08.08 |
|---|---|
| 실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기 (1) | 2018.08.07 |
| python configparser 사용하기 (0) | 2018.03.28 |
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
| Flask socketIO simple usage and code (0) | 2018.02.14 |
MacOS 에서 SIP(System Integrity Protection status) 해제하기
이번에는 맥의 시스템 파일을 건드리지 않으면 좋겠지만
필요에 의해서 건드려야 할 때 시스템 무결성을 지켜주는 보호 시스템인
SIP(System Integrity Protection status)를 간단하게 해제하는 방법을 알아보겠습니다.
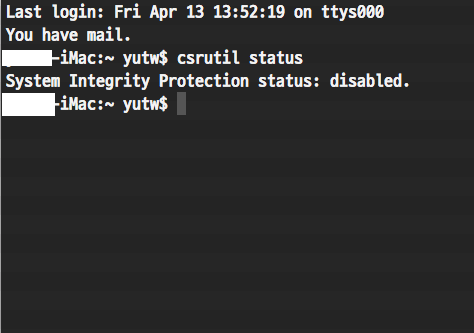
우선 위의 스크린샷은 제 맥의 SIP를 disable 시킨 상태의 모습입니다.
일단 맥의 기본 부팅 상태에서는 SIP를 해제할 수 없습니다.
재부팅을 하면서 맥의 복구모드로 진입하셔야 합니다.
맥의 사과 화면이 나오기 전에 맥이 켜지는 시점에 command + R 키를 눌러 복구모드로 진입한 뒤에
유틸리티 메뉴에서 터미널을 열어
csrutil disable
라고 입력해 줍니다.
그리고 재부팅을 해줍니다.
SIP가 비활성화 됐는지 확인하고 싶으면 csrutil status 명령어로 확인하여 위 스크린샷처럼 disabled가 나오면
완료 된 것 입니다. 끝!
'Mac' 카테고리의 다른 글
| 맥북 egpu 연동(nvidia) (0) | 2019.06.10 |
|---|---|
| MeCab 및 mecab-python 설치하기(MacOS) (0) | 2019.02.06 |
wakeonlan use by terminal(wol 리눅스에서 사용하기)
안녕하세요 이번에는 터미널로 간단히 wol을 사용하는 방법을 볼까 합니다.
네트워크 환경 - wol 패킷을 보내는 리눅스 시스템과 wol 패킷을 받아 시동이 되는 리눅스 시스템이 같은 WAN 네트워크 내에 존재
먼저. 설치를 해야 합니다.
간단한 명령어
case 1. 우분투 – sudo apt-get install wakeonlan
case 2. 맥 – brew install wakeonlan
case 3. 그 외 기타 – 소스를 다운로드하여 빌드해야 합니다. ㅜㅜ
다음으로 사용해 봅시다.
샘플 명령어 – wakeonlan 2d:3f:3a:23:1c:1b
결과 – Sending magic packet to 255.255.255.255:9 with 2d:3f:3a:23:1c:1b

위의 스크린샷은 명령 후에 결과 로그를 캡쳐한 것입니다.
부족한 제글 읽어 주셔서 감사합니다.
'etc' 카테고리의 다른 글
| 윈도우 WSL2 설정 (포트포워딩, vmmem 이슈, 시작 프로그램 등) (0) | 2021.12.25 |
|---|---|
| 우분투에 turn server 구축하기 (2) | 2019.01.27 |
| fortran 컴파일하고 사용하기 (0) | 2017.11.17 |
간단하게 보는 CPU와 GPU의 연산 차이
이번에는 요근래 하드웨어들의 스펙이 급등하면서 생기는 현상 중 병렬 프로그래밍의 본좌인 GPU와
그에 비교되는 CPU의 차이를 예전에 만들었던 PPT를 참고하여 글을 써보았습니다.
일단 기본적인 차이점을 보자면,
- CPU와는 달리 GPU는 코어가 아주 많다.
- CPU는 복잡한 계산을 빠르게 할 수 있지만 모두 직렬로 처리한다.
- GPU는 간단한 계산을 빠르게 할 수 있고, 많은 연산을 병렬로 동시에 할 수 있다.
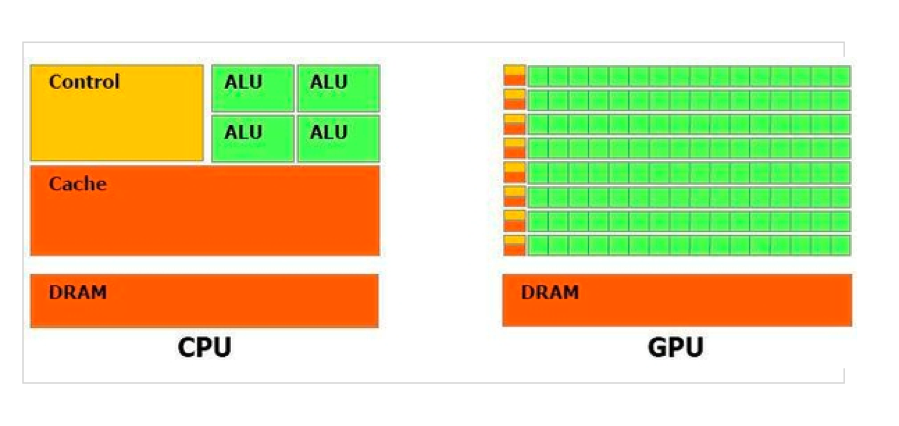
그림으로 연산하는 과정을 대략적으로 표현해 보면,

이런식입니다.
CPU와 GPU 장단점을 보면,
- CPU
- 복잡한 계산을 코어 갯수 만큼씩 처리하게 된다.
- 예로 복잡한 팩토리얼 계산식을 2개 계산해야 한다고 했을 때 CPU로 계산을 해주면 빨리할 수 있다.
- 단점 – 간단하고 많은 계산식은 오래걸린다
2. GPU
- 간단한 아주 많은 계산식을 동시에 빠르게 처리할 수 있다.
- 예로 1000개의 덧셈식을 한번에 병렬로 처리가 가능하다.
- 단점 – 초기에 알고리즘을 하드웨어에 병렬로 부여해 주어야 하고, 복잡한 식을 입력하면 도리어 CPU 연산 속도보다 느려질 수 있다.
이정도 입니다.
여기까지 간단하게 본 CPU와 GPU 연산의 차이점이었습니다.
틀린 부분이 있으면 답글 달아주시면 수정하겠습니다^^
'DeepLearning' 카테고리의 다른 글
| BERT 한국어버전(korquad) training 및 evaluating 해보기 (0) | 2019.09.04 |
|---|---|
| Python 딥러닝 관련 간단한 활성화 함수 (0) | 2018.02.20 |
(초)미세먼지 마스크 2종 비교
요 몇년 사이 미세먼지 및 초미세먼지가 계절을 가리지 않고 공기를 뒤덮고 있는데요.
이로 인해 저도 제 목숨?과 건강이 중요하기 때문에 호흡기를 보호하기 위해 여러가지 마스크를 구매하여 착용하여 보았는데요.
제가 사용했던 2가지 마스크 후기를 써봅니다.

두 제품 다 온라인 구매하였습니다.
두제품 모두 코부분에 유연한 얇은 금속이 있어 조절하여 밀착력을 높일 수 있습니다.
—————————————————————————————————-
1. 크리넥스 KF94 대형
이 제품은 2017년 초기부터 처음사서 쓰고 댕겼습니다. 일단 가격은 1매당 2천원대 초반으로 형성되어 있습니다.
착용할 때 양쪽의 귀에 거는 끈한쪽에 고리가 있습니다. 이 고리를 처음에는 모르고 그냥 버렸는데,
착용법을 읽고 깜짝 놀라서 사용하기 시작했습니다. 이 양쪽의 끈을 귀에 거는 것이 아니라 머리뒤로 끈을
잡아당겨서 고리로 걸어주는 것이었습니다. 이 착용법으로 마스크 밀착력이 올라갑니다.
비싼? 가격답게 착용하면 숨쉬기가 조금 갑갑할 정도로 촘촘한 미세먼지 필터링을 자랑합니다.
착용하고 나서 출발지에서 도착지까지 이동하고 나면 마스크 안이 입김때문에 습해 집니다.
약간 불편한만큼 이 제품을 착용하고 다니면 미세먼지는 잘 걸러지는 효과를 느꼈습니다.
외출을 하고 집에 와도 목이 간지럽지 않았습니다.
2. 모나리자 KF94 대형
이 제품은 2018년 처음 사용해 보았는데요. 가격은 1매당 1천원이 조금 안되거나 1천원 정도에 형성되어 있습니다.
착용할 때 양쪽에 귀에 걸게 되어 있습니다. 이 제품은 위의 제품과 달리 고리는 없었지만 착용하면 편하게 착용할 수 있었습니다.
위의 제품과 달리 약간은 밀착력이 떨어지지만 마스크면의 부직포는 확실히 미세먼지를 잘 걸러주었습니다.
착용하면 약간 헐렁한 느낌이 있어 가끔 헐렁해지면 조금씩 공기가 세는 느낌?이 있었습니다.
결론은 미세먼지가 아주 약간씩 세는 느낌이 있었습니다.
저는 그래서 1번 제품을 다쓰고 고리만 빼내어 2번제품에 고리를 걸어 사용하기도 하였습니다.
두 제품이 다른면에서 서로 장점을 나타내 주는데요,
현재 저는 두 제품 다 비슷한 수량만큼 가지고 있고, 두 제품 다 번갈아 가면서 사용하고 있습니다. 여기서 후기 끝~!
'life' 카테고리의 다른 글
| 2020년 가을 제주도 나홀로 여행 기록(숙박, 카페, 느낌, 일) (0) | 2020.10.11 |
|---|---|
| 메모의 힘 (0) | 2019.11.05 |
python configparser 사용하기
프로젝트를 하다보면 프로젝트의 설정 파일을 만들어 줘야 할 때가 있습니다.
그럴 때 유용한 것이 있으니 그것은 바로 python의 기본 내장 모듈 configparser 입니다.
여기서 간단하게 configparser를 다뤄보고자 합니다.
우선 임포트를 해줍니다.
import configparser config = configparser.ConfigParser()
그리고 만들어 둔 설정 파일을 configparser로 읽어 줍니다.
config.read('/home/python_user/server.conf')
여기서 읽어 오는 샘플 설정 파일인 server.conf 를 보자면
[MAIN] project_root = /home/python_user/project/api_server/ db_host = 127.0.0.1 db_port = 3306 db_user = test_user db_passwd = test_passwd db_name = test_db temp_path =/home/python_user/temp/ image_path =/home/python_user/image/
이러한 식으로 MAIN이라는 카테고리를 만든 후 그 아래 여러가지 설정값들을 넣었습니다.
그리고 읽어들인 설정을 사용하려면
config = config['MAIN']
여기서 MAIN 카테고리를 선택 후
project_root_path = config['project_root']
이런식으로 project_root_path라는 변수에 project_root 설정값을 저장할 수 있습니다.
이 방식이 아닌 다른 방식도 있지만 저는 주로 이 방식을 즐겨 사용합니다.
전체 코드는 아래에~
import configparser
config = configparser.ConfigParser()
config.read('/home/python_user/server.conf')
config = config['MAIN']
project_root_path = config['project_root']
참 쉽죠?
저는 처음에 헤매었다가 지금은 즐겨 사용하고 있습니다. 끝~!
'Python' 카테고리의 다른 글
| 실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기 (1) | 2018.08.07 |
|---|---|
| Python sounddevice를 이용한 소리 탐지 (0) | 2018.04.23 |
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
| Flask socketIO simple usage and code (0) | 2018.02.14 |
| python multiprocessing 사용하기 (1) | 2018.02.12 |
NodeJS로 간단한 채팅 서버 구축하기
이번에는 지인과 함께 간단한 앱을 만들면서 생성하게 된 채팅서버를 공개해 봅니다.
바로 갑니다앙~!
var app = require('http').createServer(handler);
var fs = require('fs');
var io = require('socket.io').listen(app);우선 http와 나중에 사용할 fs, 그리고 필수 라이브러리인 socket.io를 import 합니다.
if (process.argv.length < 3){
console.log('app <port>');
process.exit(1);
}
app.listen(process.argv[2]);
console.log(process.argv[2] +' Started!! ');
function handler(req, res) {
fs.readFile(__dirname + '/index.html',
function (err, data) {
if (err) {
res.writeHead(500);
return res.end('Error loading index.html');
}
res.writeHead(200);
data = data.toString('utf-8').replace('<%=host%>', req.headers.host);
res.end(data);
});
}그리고 렌더링할 index.html 파일 경로를 설정해주고, 렌더링 코드를 입력해 줍니다.
process.argv로는 매개변수로 포트를 설정할 수 있도록 합니다.
그 다음으로 socket.io 코드를 작성합니다.
io.sockets.on('connection', function (socket) {
fs.readFile( __dirname + "/../data/chat.json", "utf8", function (err, data) {
prev_data = JSON.parse(data);
socket.emit('init', prev_data);
console.log(prev_data);
});
socket.on('message', function(data){
var split_cnt = prev_data.length;
if(split_cnt > 10){ // 저장될 채팅메시지의 갯수
prev_data.splice(0,1);
}
prev_data.push(data);
fs.writeFile( __dirname + "/../data/chat.json", JSON.stringify(prev_data), function(err) {
// throws an error, you could also catch it here
if (err) throw err;
// success case, the file was saved
});
socket.broadcast.emit('message', data);
});
});chat.json은 서버상에 저장될 채팅 메시지를 json 파일로 저장하는 역할을 합니다.
경로는 여러분이 원하는 곳에 놔두셔도 됩니다.
그리고 중간에 저장될 채팅메시지 갯수를 지정할 수 있는데요. 배열 길이와 일치하도록 했습니다.
이것 또한 여러분이 커스터마이징 하시면 됩니다.
요 위까지 서버측 코드입니다.
——————————————————————————————-
이제 아래로 클라이언트 코드입니다.
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
<title>socket io redis store</title>
<script type="text/javascript" src="http://code.jquery.com/jquery-1.10.1.min.js"></script>
<script type="text/javascript" src="/socket.io/socket.io.js"></script>
<script>
var socket = io.connect('http://<%=host%>');
$(document).ready(function(){
socket.on('init',function(data){
for(var i=0; i<data.length; i++){
console.log(data[i]);
$('#chat').append('<li>' + data[i] + '</li>');
}
});
socket.on('message',function(data){
$('#chat').append('<li>' + data + '</li>');
});
$('#btnSend').click(function(){
send();
});
$('#inputT').keyup(function(e){
if(e.keyCode == 13)
send();
});
});
function send() {
var message = $('#inputT').val();
if (message.length < 1) return;
socket.emit('message', message);
$('#chat').append('<li>'+message+'</li>');
$('#inputT').val('');
}
</script>
</head>
<body>
<input type="text" id="inputT" />
<button id="btnSend">보내기</button>
<ul id="chat"></ul>
</body>
</html>코드 작성을 완료하였으면 실행을 해줍니다.
node index.js 3000
저는 3000번 포트로 실행시켰습니다.
끝~
'JavaScript > NodeJS' 카테고리의 다른 글
| NodeJS의 forever 모듈 설치하고 다루기 (0) | 2017.11.12 |
|---|
Python 딥러닝 관련 간단한 활성화 함수
딥러닝 공부를 하는 중이나 복습 차 python코드로 된 활성화 함수 몇가지를 올려봅니다.
여기서 활용하는 함수들의 출처는 – 밑바닥부터 시작하는 딥러닝 – 에서 참고하였습니다.
일단 신경망의 기초가 되는 퍼셉트론에서는 활성화 함수로 계단 함수를 이용한다라 할 수 있습니다.
python으로 구현하는 간단한 계단함수 코드는
def step_function(x):
if x > 0:
return 1
else:
return 0가 되겠습니다.
x가 0을 기준으로 0과 1로 결과값이 나눠집니다.
이 코드를 numpy를 사용하여 더 편하게 사용하려면
import numpy as np
def step_function(x):
return np.array(x > 0, dtype=np.int)로 사용하시면 되겠습니다.
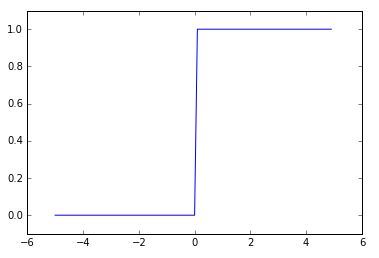
결과값이 true 또는 false로 분기되는 것을 dtype=np.int를 통해 정수형으로 형변환을 시켜주는 원리입니다.
여기까지는 계단함수를 보았습니다.
다음은 시그모이드 함수 구현입니다.
시그모이드의 공식은 아래와 같습니다.

이것을 numpy를 통해 쉽게 코드로 구현하면
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))그래프는 아래와 같이 나옵니다.
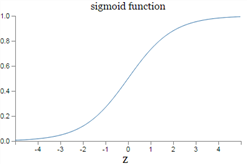
마지막으로 (ReLU)렐루 함수를 보겠습니다.
렐루 함수는 0이하이면 0을 출력, 0을 넘으면 그대로의 값을 출력하는 함수입니다.
렐루 함수는 파이썬 코드로 상당히 간결하게 구현이 가능합니다.
import numpy as np
def relu(x):
return np.maximum(0, x)위와 같이 0과 값중에 최대값을 출력하면 렐루 함수가 됩니다.

여기까지 간단한 Python코드로 구현해보는 활성화 함수 세가지를 보았습니다.
'DeepLearning' 카테고리의 다른 글
| BERT 한국어버전(korquad) training 및 evaluating 해보기 (0) | 2019.09.04 |
|---|---|
| 간단하게 보는 CPU와 GPU의 연산 차이 (0) | 2018.03.29 |
