간단한 python 이메일 연동하기
안녕하세요 2019년 새해 첫 포스팅은 이메일에 관한 글입니다.
주제는 파이썬으로 이메일 연동하기입니다.
이메일은 크게 smtp(발신) / pop, imap(수신) 프로토콜을 이용해서 전송 및 수신을 합니다.
저는 몇 일간의 삽질을 바탕으로 받고 보내는 함수를 만들었습니다.
이를 바탕으로 여러분도 응용하여 이메일을 손쉽게 제어하시기 바랍니다.
자, 이제 소스를 공개!
import smtplib
import imaplib
import poplib
import email
from email.mime.text import MIMEText
from datetime import datetime
# 보낼 곳과 연동할 이메일 계정
sendto = '받는사람@이메일.com'
user = '보내는사람@이메일.com'
password = "보내는사람 이메일 패스워드"
# 메일을 보내는 함수(smtp)
def send_mail(user, password, sendto, msg_body):
# smtp server
smtpsrv = "smtp.office365.com" # 발신 메일서버 주소
smtpserver = smtplib.SMTP(smtpsrv, 587) # 발신 메일서버 포트
smtpserver.ehlo()
smtpserver.starttls()
smtpserver.login(user, password)
msg = MIMEText(msg_body)
msg['From'] = user
msg['To'] = sendto
msg['Subject'] = "Module Testing email Subject"
smtpserver.sendmail(user, sendto, msg.as_string())
print('done!')
smtpserver.close()
# 메일을 받는 함수(imap4)
def check_mail_imap(user, password):
# imap server
imapsrv = "outlook.office365.com"
imapserver = imaplib.IMAP4_SSL(imapsrv, "993")
imapserver.login(user, password)
imapserver.select('INBOX')
res, unseen_data = imapserver.search(None, '(UNSEEN)')
ids = unseen_data[0]
id_list = ids.split()
latest_email_id = id_list[-10:]
# 메일리스트를 받아서 내용을 파일로 저장하는 함수
for each_mail in latest_email_id:
# fetch the email body (RFC822) for the given ID
result, data = imapserver.fetch(each_mail, "(RFC822)")
msg = email.message_from_bytes(data[0][1])
while msg.is_multipart():
msg = msg.get_payload(0)
content = msg.get_payload(decode=True)
f = open("email_" + str(datetime.now()) + ".html", "wb")
f.write(content)
f.close()
imapserver.close()
imapserver.logout()
# 메일을 받는 함수(pop)
def check_mail_pop(user, password):
# imap server
popsrv = "pop.test.kr"
popserver = poplib.POP3(popsrv, "110")
popserver.user(user)
popserver.pass_(password)
numMsg = len(popserver.list()[1])
for i in range(numMsg):
raw_email = b"\n".join(popserver.retr(i + 1)[1])
msg = email.message_from_bytes(raw_email)
while msg.is_multipart():
msg = msg.get_payload(0)
content = msg.get_payload(decode=True)
f = open("email_" + str(datetime.now()) + ".html", "wb")
f.write(content)
f.close()
popserver.close()
if __name__ == '__main__':
# imap형식 수신 함수
check_mail_imap(user, password)
# pop형식 수신 함수
check_mail_pop(user, password)
# 메일을 보내는 함수 smtp
send_mail(user, password, sendto, "안녕하세요 코코넛이 이메일을 보냅니다.")여기까지 저는 수신한 이메일을 파일로 저장하는 소스를 만들었는데요.
여러분 입맛대로 수정해서 쓰시면 됩니다.
'Python' 카테고리의 다른 글
| Python을 이용한 엑셀 읽기 및 쓰기(xlrd, xlwt) (0) | 2019.06.10 |
|---|---|
| zappa를 이용한 파이썬 서버리스 구현 (0) | 2019.02.14 |
| python socket(tcp, udp) 사용하기 (0) | 2018.12.02 |
| linux 파일 동기화 소스 auto_sync (0) | 2018.09.09 |
| Python패키지 목록 requirements.txt 관리하기 (0) | 2018.08.08 |
python socket(tcp, udp) 사용하기
이번에는 python에서 기본으로 제공하는 socket 모듈을 사용하는 방법을 다루겠습니다.
socket 통신에는 tcp와 udp 두가지가 있습니다.
1. 먼저 tcp – sender
# socket module import!
import socket
# socket create and connection
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(("123.123.123.123", 9999))
# send msg
test_msg = "안녕하세요 상대방님"
sock.send(test_msg)
# recv data
data_size = 512
data = sock.recv(data_size)
# connection close
sock.close()우선 tcp는 위에 모듈을 임포트 한 뒤에 소켓 통신을 할 ip(저는 임의로 123.123.123.123)와 포트를 지정 후에
연결을 합니다.
연결이 성사 되면 test_msg를 send합니다. 그리고 send가 끝나는 동시에 data를 data_size만큼 받아오게 됩니다.
이렇게 tcp를 사용할 수 있습니다. 상황에 맞게 for루프를 돌리거나 수정해서 사용하면 됩니다.
2. tcp – receiver
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
recv_address = ('0.0.0.0', 9999)
sock.bind(recv_address)
sock.listen(1)
conn, addr = s.accept()
# recv and send loop
while 1:
data = conn.recv(BUFFER_SIZE)
# 받고 data를 돌려줌.
conn.send(data)
conn.close()받는 쪽 즉, 서버쪽의 tcp 소스 입니다.
3. 그리고 udp – sender
import socket
# connection create
send_sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
dest = ("127.0.0.1", 9999)
# send to dest
send_sock.sendto(data, dest)
send_sock.close()위에 소스는 출발지 소켓 소스입니다.
4. udp – receiver
import socket
# socket create
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# Bind the socket to the port
recv_address = ('0.0.0.0', 9999)
sock.bind(recv_address)
data_size = 512
data, sender = sock.recvfrom(data_size)
sock.close()위 소스는 목적지 소켓 소스입니다.
끝~!
'Python' 카테고리의 다른 글
| zappa를 이용한 파이썬 서버리스 구현 (0) | 2019.02.14 |
|---|---|
| 간단한 python 이메일 연동하기 (0) | 2019.01.27 |
| linux 파일 동기화 소스 auto_sync (0) | 2018.09.09 |
| Python패키지 목록 requirements.txt 관리하기 (0) | 2018.08.08 |
| 실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기 (1) | 2018.08.07 |
Python패키지 목록 requirements.txt 관리하기
안녕하세요 이번에는 Python의 패키지 환경을 쉽게 관리할 수 있도록 도와주는
requirements.txt 을 간단하게 소개하고자 합니다.
파이썬을 쓰면서 가끔 불편한 것이 새로운 환경에 자신이 설치하고자 하는 파이썬 패키지를
일일히 구성해주는 일이 불편할텐데요.
그것을 쉽게 관리해주는 것이 바로 requirements.txt 입니다.
우선 자신이 구성한 환경을 requirements.txt 로 만드는 명령어는
pip freeze > requirements.txt
입니다.
그러면 설치되있는 패키지들이 알파벳순으로 requirements.txt 로 저장이 됩니다.
그리고 이 requirements.txt 를 반대로 지정한 환경에 설치하는 방법은
pip install -r requirements.txt
입니다.
이 명령어로 설치가 안되는 패키지도 있습니다.
다른 패키지에 대한 의존성이라든지 여러가지 요소로 설치가 안되는 패키지는 수동으로 설치를 해주시면 됩니다.
이 것으로 requirements.txt 에 대해 마치겠습니다~~
'Python' 카테고리의 다른 글
| python socket(tcp, udp) 사용하기 (0) | 2018.12.02 |
|---|---|
| linux 파일 동기화 소스 auto_sync (0) | 2018.09.09 |
| 실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기 (1) | 2018.08.07 |
| Python sounddevice를 이용한 소리 탐지 (0) | 2018.04.23 |
| python configparser 사용하기 (0) | 2018.03.28 |
실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기
안녕하세요 뜨거운 여름동안 잘 쉬다가 오랜만에 포스팅을 하게 되었습니다.
이번에는 제가 개인적으로 진행하고 있는 프로젝트의 소스와 내용을 포스팅하게 되었습니다.
그 내용은 제목에 있습니다. 자세히 표현하자면 네이버 뉴스를 1시간마다 크롤링하여
크롤링한 뉴스의 내용을 엘라스틱 서치라는 검색엔진 API로 뿌려주는 겁니다.
일단 사전에 환경이 준비되어 있어야 합니다. 그 환경은 아래에 기재하였습니다.
- 엘라스틱서치를 설치하고 실행까지 해주셔야 합니다.
- Beautifulsoup와 pandas와 같은 파이썬 패키지를 설치해 주셔야 합니다.
- REST API로 api를 구현하되 원하는 프레임워크 및 라이브러리로 구현을 해주시면 됩니다.(저는 nodeJS의 Express로 구현 하였습니다.)
- 위의 내용들은 저의 환경이니 각자 원하시는 환경으로 커스터마이징 하셔도 됩니다.
일단 뉴스 내용을 수집해야 하니 크롤러부터 들어갑니다.
바로 소스코드 공개합니다.
realtime.py
#-*- coding: utf-8 -*-
import os
import sys
from bs4 import BeautifulSoup
from urllib.request import urlopen
from datetime import datetime, timedelta
from traceback import format_exc
dir = os.path.dirname(__file__)
sys.path.insert(0, os.path.join(dir, '../save'))
import pandas_csv
import to_es
base_url = "http://news.naver.com/#"
def collecting(base_url):
data = urlopen(base_url).read()
soup = BeautifulSoup(data, "html.parser")
total_data = soup.find_all(attrs={'class': 'main_component droppable'})
colect_time = str(datetime.utcnow().replace(microsecond=0) + timedelta(hours=9))[:16]
for each_data in total_data:
category = ""
try:
category = str(each_data.find_all(attrs={'class': 'tit_sec'})).split('>')[2][:-3]
except:
pass
data = str(each_data.find_all(attrs={'class': 'mlist2 no_bg'}))
news_list = data.split('<li>')
for each_news in news_list[1:]:
news_block = each_news.split('href="')[1]
# print(news_block)
title = news_block.split('<strong>')[1].split('</strong>')[0]
# print(title)
news_url = news_block.split('"')[0].replace("amp;", "")
# print(news_url)
soup2 = BeautifulSoup(urlopen(news_url).read(), "html.parser")
# print(soup2)
# article_info = soup2.find_all(attrs={'class': 'article_info'})
# print(article_info)
article_body = str(soup2.find_all(attrs={'id': 'articleBodyContents'}))
insert_data = {"source": "naver_news",
"category": category,
"title": title,
"article_body": article_body,
"colect_time": colect_time}
pandas_csv.to_csv(insert_data)
to_es.to_elastic(insert_data)
collecting(base_url)위의 realtime.py는 한번 실행시키면 네이버 뉴스의 여러 카테고리의 뉴스들을 좌악~ 크롤링해 옵니다.
그리고 가져온 내용들은 for문을 돌며 각 뉴스 기사 단위로 insert_data라는 딕셔너리에 저장이 됩니다.
저는 이 딕셔너리를 csv와 elastic search 에 저장을 하게 코드를 짜 놓았습니다.
엘라스틱서치에 저장하는 소스코드는
pandas_csv.py
import os
import pandas as pd
from datetime import datetime, timedelta
import configparser
import glob
config = configparser.ConfigParser()
config.read('/home/yutw/project/searchnews/crawler/crawler.conf')
def to_csv(data):
pathlink ="/home/yutw/data/searchnews"
# db create
if not os.path.isdir(pathlink):
os.mkdir(pathlink)
present_date = str(datetime.utcnow() + timedelta(hours=9))[:10]
# col = ["source", "category", "title", "article_body", "colect_time"]
if len(glob.glob(pathlink + "/" + present_date + ".csv")) == 1:
cnt = len(pd.read_csv(pathlink + "/" + present_date + ".csv", index_col=0).index)
time_pd = pd.DataFrame(data, index=[cnt])
time_pd.to_csv(pathlink + "/" + present_date + ".csv", mode='a', header=False)
else:
cnt = 0
time_pd = pd.DataFrame(data, index=[cnt])
time_pd.to_csv(pathlink + "/" + present_date + ".csv", mode='a')
요 위까지 csv로 내용을 저장해 줍니다.
그리고 엘라스틱서치에도 insert를 해줍니다.
to_es.py
from elasticsearch import Elasticsearch
es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
import json
import configparser
from datetime import datetime, timedelta
import pandas as pd
config = configparser.ConfigParser()
config.read('/home/yutw/project/searchnews/crawler/crawler.conf')
def to_elastic(data):
pathlink = "/home/yutw/data/searchnews"
present_date = str(datetime.utcnow() + timedelta(hours=9))[:10]
del_date = str(datetime.utcnow() - timedelta(hours=39))[:10]
cnt = len(pd.read_csv(pathlink + "/" + present_date + ".csv", index_col=0).index)
es.index(index="searchnews", doc_type='naver_news', id=present_date + "-" + str(cnt), body=json.dumps(data))
if cnt == 1:
days = [x for x in range(1, int(del_date[-2:]))]
for day in days:
if len(str(day)) == 1:
for each in range(1, 1500):
try:
es.delete(index="searchnews", doc_type="naver_news", id=del_date[:8] + '0' + str(day) + "-" + str(each))
except:
pass
else:
for each in range(1, 1500):
try:
es.delete(index="searchnews", doc_type="naver_news", id=del_date[:8] + str(day) + "-" + str(each))
except:
pass
이 후에 저장한 내용을 API로 뿌려주면 되는데요.
여기서 저는 Express 의 api를 사용해서 간단하게 API서버를 구현하였습니다.
우선 Express 기본 샘플 프로젝트를 만들어 줍니다.
https://github.com/gothinkster/node-express-realworld-example-app.git
이 곳을 통해 내려받거나 원하는 형태의 소스코드를 받으시고
api쪽(저는 routes의 디렉터리 안에 구성하였습니다.)
index.js
var express = require('express');
var fs = require('fs');
var router = express.Router();
var elasticsearch = require('elasticsearch');
var client = new elasticsearch.Client({
host: 'localhost:9200',
log: 'trace'
});
/* GET home page. */
router.get('/', function(req, res, next) {
res.render('index', { title: 'Express' });
});
router.get('/newsSearch/:keyword', function (req, res) {
client.search({
q: req.params.keyword
}).then(function (body) {
var hits = body.hits.hits;
res.json(hits);
}, function (error) {
console.trace(error.message);
});
});
router.get('/user', function (req, res) {
var value = {"test": "user"};
console.log(value);
res.json(value);
});
module.exports = router;
API 또한 원하는 방향으로 해주시면 됩니다. 위의 소스코드는 keyword에 따라 모두 검색할 수 있게 코드를 작성하였습니다.
이제 API서버도 동작시켜 줍니다.
그러면 모두 완료되었습니다. python realtime.py 를 실행하면 크롤링이 되고 자동으로 엘라스틱서치에도 insert가 되어 api서버에서 keyword를 검색하면 키워드에 맞는 뉴스들이 검색이 됩니다.

이런식으로 request를 보내면

이렇게 json형식으로 response가 떨어집니다. 여기까지 제 방식대로 코딩했는데요. 원하시는 내용을 코드를 편집해서 쓰셔도 됩니다.
여기까지 포스팅을 마칩니다.
'Python' 카테고리의 다른 글
| linux 파일 동기화 소스 auto_sync (0) | 2018.09.09 |
|---|---|
| Python패키지 목록 requirements.txt 관리하기 (0) | 2018.08.08 |
| Python sounddevice를 이용한 소리 탐지 (0) | 2018.04.23 |
| python configparser 사용하기 (0) | 2018.03.28 |
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
python configparser 사용하기
프로젝트를 하다보면 프로젝트의 설정 파일을 만들어 줘야 할 때가 있습니다.
그럴 때 유용한 것이 있으니 그것은 바로 python의 기본 내장 모듈 configparser 입니다.
여기서 간단하게 configparser를 다뤄보고자 합니다.
우선 임포트를 해줍니다.
import configparser config = configparser.ConfigParser()
그리고 만들어 둔 설정 파일을 configparser로 읽어 줍니다.
config.read('/home/python_user/server.conf')
여기서 읽어 오는 샘플 설정 파일인 server.conf 를 보자면
[MAIN] project_root = /home/python_user/project/api_server/ db_host = 127.0.0.1 db_port = 3306 db_user = test_user db_passwd = test_passwd db_name = test_db temp_path =/home/python_user/temp/ image_path =/home/python_user/image/
이러한 식으로 MAIN이라는 카테고리를 만든 후 그 아래 여러가지 설정값들을 넣었습니다.
그리고 읽어들인 설정을 사용하려면
config = config['MAIN']
여기서 MAIN 카테고리를 선택 후
project_root_path = config['project_root']
이런식으로 project_root_path라는 변수에 project_root 설정값을 저장할 수 있습니다.
이 방식이 아닌 다른 방식도 있지만 저는 주로 이 방식을 즐겨 사용합니다.
전체 코드는 아래에~
import configparser
config = configparser.ConfigParser()
config.read('/home/python_user/server.conf')
config = config['MAIN']
project_root_path = config['project_root']
참 쉽죠?
저는 처음에 헤매었다가 지금은 즐겨 사용하고 있습니다. 끝~!
'Python' 카테고리의 다른 글
| 실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기 (1) | 2018.08.07 |
|---|---|
| Python sounddevice를 이용한 소리 탐지 (0) | 2018.04.23 |
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
| Flask socketIO simple usage and code (0) | 2018.02.14 |
| python multiprocessing 사용하기 (1) | 2018.02.12 |
Python 딥러닝 관련 간단한 활성화 함수
딥러닝 공부를 하는 중이나 복습 차 python코드로 된 활성화 함수 몇가지를 올려봅니다.
여기서 활용하는 함수들의 출처는 – 밑바닥부터 시작하는 딥러닝 – 에서 참고하였습니다.
일단 신경망의 기초가 되는 퍼셉트론에서는 활성화 함수로 계단 함수를 이용한다라 할 수 있습니다.
python으로 구현하는 간단한 계단함수 코드는
def step_function(x):
if x > 0:
return 1
else:
return 0가 되겠습니다.
x가 0을 기준으로 0과 1로 결과값이 나눠집니다.
이 코드를 numpy를 사용하여 더 편하게 사용하려면
import numpy as np
def step_function(x):
return np.array(x > 0, dtype=np.int)로 사용하시면 되겠습니다.
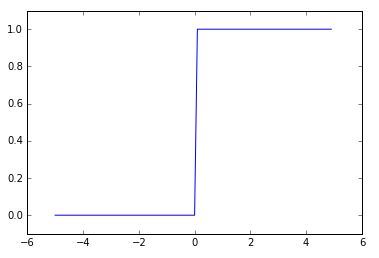
결과값이 true 또는 false로 분기되는 것을 dtype=np.int를 통해 정수형으로 형변환을 시켜주는 원리입니다.
여기까지는 계단함수를 보았습니다.
다음은 시그모이드 함수 구현입니다.
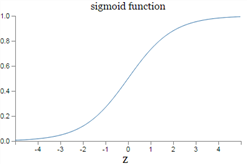
시그모이드의 공식은 아래와 같습니다.

이것을 numpy를 통해 쉽게 코드로 구현하면
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))그래프는 아래와 같이 나옵니다.
마지막으로 (ReLU)렐루 함수를 보겠습니다.
렐루 함수는 0이하이면 0을 출력, 0을 넘으면 그대로의 값을 출력하는 함수입니다.
렐루 함수는 파이썬 코드로 상당히 간결하게 구현이 가능합니다.
import numpy as np
def relu(x):
return np.maximum(0, x)위와 같이 0과 값중에 최대값을 출력하면 렐루 함수가 됩니다.

여기까지 간단한 Python코드로 구현해보는 활성화 함수 세가지를 보았습니다.
'DeepLearning' 카테고리의 다른 글
| BERT 한국어버전(korquad) training 및 evaluating 해보기 (0) | 2019.09.04 |
|---|---|
| 간단하게 보는 CPU와 GPU의 연산 차이 (0) | 2018.03.29 |
Django 에서의 간단한 마이그레이션 과정
이번에는 django 프레임워크의 디비에 관한 강력한 기능이자 장점인 orm 기능의
마이그레이션에 관해 간단하게 알아보고자 합니다.
- 우선 models.py 파일을 만들어서 디비 스키마를 넣어주는 방법이 있습니다. 이 방법은 models.py 안에 여러가지 스키마를 넣어주는 방법인데요.
- 조금 더 규모가 크거나 테이블별로 파일을 생성하신다 하면 models 라는 파이썬 패키지를 생성해주고, 그안에 테이블별로 파일을 생성해 주셔도 됩니다.
여기서는 2번에 관하여 마이그레이션을 진행할 것 입니다.
우선 models라는 패키지 안에 user.py 라는 테이블 파일을 생성해줍니다.
그리고 그 안에 User 모델 클래스를 생성하고 간단한 스키마를 작성하였습니다.
from django.db import models
from django.utils import timezone
class User(models.Model):
user_id = models.CharField(max_length=100, primary_key=True)
email = models.CharField(max_length=100, default="")
name = models.CharField(max_length=30, default="")
gender = models.CharField(max_length=10, default="남자")
age = models.DateTimeField(max_length=100, default=timezone.now)
country = models.CharField(max_length=100, default="")
etc = models.TextField(default=None, null=True)
group = models.CharField(max_length=50, default="client")
그리고 같은 경로 상에 __init__.py 파일이 존재해야 하는데요

__init__.py 파일 안에
from .user import *
로 작성해 줍니다.
이제 위 모델패키지가 존재하는 앱을 django settings.py에 포함을 시켜줍니다.(이미 있다면 안하셔도 됩니다.)
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'앱이름',
'client',
]여기까지 완료되었다면 django 마이그레이션 파일을 django가 생성하도록 스크립트를 콘솔상에서 실행해줍니다.
python manage.py makemigrations '앱이름'
스크립트 실행 후에 앱 패키지 안에 migrations 디렉터리가 자동으로 생성되고 그 안에 마이그레이션 파일도 생성됩니다.
여기까지 마이그레이션 파일 생성 과정입니다.
후에 settings.py 파일 안에 있는 디비 정보와 매칭되는 디비정보가 같다면 바로 마이그레이트까지 가능합니다.
디비에 스키마를 반영하고 싶다면 아래 스크립트를 실행하여 주면 됩니다.
python manage.py migrate
'Python' 카테고리의 다른 글
| Python sounddevice를 이용한 소리 탐지 (0) | 2018.04.23 |
|---|---|
| python configparser 사용하기 (0) | 2018.03.28 |
| Flask socketIO simple usage and code (0) | 2018.02.14 |
| python multiprocessing 사용하기 (1) | 2018.02.12 |
| Pandas DataFrame를 csv로 저장하고 로드하기 (0) | 2017.11.12 |
Flask socketIO simple usage and code
socketIO 관련 프로젝트를 하면서 NodeJS를 처음부터 사용할 생각은 아니었지만
어쩌다가 Flask를 이용한 socketIO를 사용하게 되어 간단한 구조를 살펴보고 제가 작성한 코드를
올리려고 합니다.
우선 이 Flask socketIO란 놈은 구버전 익스플로러같은 곳에서는 수신이 안될 수 있으니 주의하시기 바랍니다.
저도 그것때문에 NodeJS socketIO로 바꿨습니다. 그것 빼고는 아주 무난하게 동작합니다.
from flask import Flask, render_template from flask_socketio import SocketIO, emit
우선 해당 라이브러리들을 임포트해줍니다.
그리고 플라스크 socketIO 객체를 생성합니다.
app = Flask(__name__) app.config['SECRET_KEY'] = 'secret!' socketio = SocketIO(app)
그리고 밑에 코드는 써도 좋고 안써도 좋습니다. 결과를 관찰하기 위해 html 템플릿을 렌더시킨 것이기 때문입니다.
@app.route('/')
def index():
return render_template('data.html')
그리고 run을 시켜주면 되는데요.
global app socketio.run(app, host='0.0.0.0', port=5555)
저는 포트넘버를 5555로 잡았습니다.
그리고 간단한 수신부 코드를 만들어 보았습니다. 수신부 명을 ‘real_time’ 이라고 임의로 지어 주고, send_data라는 함수명은 아무렇게 지어줘도 상관없습니다.
그리고 함수명 옆에 message라는 파라미터는 발신부에서 보내주는 데이터를 받아올 수 있는 파라미터입니다.
@socketio.on('real_time')
def send_data(message):
from datetime import datetime
global timecheck
global result
try:
now = str(datetime.utcnow().replace(microsecond=0))
if timecheck == now:
emit('fromserver', json.dumps({'data': result['data']}))
else:
get = {"time": now}
result = db["buffer"].find_one(get)
emit('fromserver', json.dumps({'data': result['data']}))
timecheck = now
# exception handling
except:
# db.close()
print("occur exeption" + format_exc())저는 수신부와 연결된 모든 클라이언트에게 전송할 것이기 때문에 emit함수를 사용하였는데요, 사용 목적에 따라 함수 선택 해주시면 됩니다.
자세한 설명은 flask-socketIO 문서를 참고하세요.
이 단락의 코드를 간단히 설명하자면 ‘real_time’ 이라는 수신부로 받은 소켓데이터에서 message 파라미터는 이용하지 않았지만 현재 시간을 기준으로 db[“buffer”]에 있는 데이터를 얻어 json으로 파싱하여 모든 클라이언트에 전송하는 로직의 코드입니다.
풀 소스코드는 아래에 첨부하였습니다.
# -*- coding: utf8 -*-
import multiprocessing
import pandas as pd
from pandas.tseries.offsets import Hour, Minute, Second
import json
from traceback import format_exc
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client['seismic']
timecheck = ""
result = []
from flask import Flask, render_template
from flask_socketio import SocketIO, emit
app = Flask(__name__)
app.config['SECRET_KEY'] = 'secret!'
socketio = SocketIO(app)
@app.route('/')
def index():
return render_template('data.html')
class IO_Socket(multiprocessing.Process):
"""client connection generator"""
def __init__(self):
"""
constructor for multiprocessing
"""
multiprocessing.Process.__init__(self)
self.__suspend = False
self.__exit = False
def run(self):
"""Process start method"""
# wrap Flask application with socketio's middleware
global app
socketio.run(app, host='0.0.0.0', port=5555)
def mySuspend(self):
self.__suspend = True
def myResume(self):
self.__suspend = False
def myExit(self):
self.__exit = True
@socketio.on('real_time')
def send_data(message):
from datetime import datetime
global timecheck
global result
try:
now = str(datetime.utcnow().replace(microsecond=0) + Hour(9) - Second(5))
if timecheck == now:
emit('fromserver', json.dumps({'data': result['data']}))
else:
get = {"time": now}
result = db["buffer"].find_one(get)
emit('fromserver', json.dumps({'data': result['data']}))
timecheck = now
# exception handling
except:
# db.close()
print("occur exeption" + format_exc())
# pass
# else:
# print('off mode')
# pass
# else:
# send_by_time(message)
전체 코드 중에서 몽고 디비를 같이 쓰긴 했지만 쓰시는 목적에 따라 코드 변경해 주시면 됩니다.
'Python' 카테고리의 다른 글
| python configparser 사용하기 (0) | 2018.03.28 |
|---|---|
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
| python multiprocessing 사용하기 (1) | 2018.02.12 |
| Pandas DataFrame를 csv로 저장하고 로드하기 (0) | 2017.11.12 |
| python BeautifulSoup 이용한 간단한 크롤링 (0) | 2017.11.12 |
python multiprocessing 사용하기

이번에는 python의 GIL문제에 대응하여 병렬로 작업을 처리할 수 있는 파이썬 내장 라이브러리인 multiprocessing 에 대해 끄적여 보겠습니다.
python의 multiprocessing을 사용하는 방법은 간단합니다. threading을 사용하는 방법과 비슷합니다.
우선
import multiprocessing
하여 multiprocessing 을 가져와 줍니다.
그리고, 저는 클래스 방식으로 구현을 할 것인데요, 제가 사용하고 있는 소스코드를
가져와 봤습니다.
class DemoClass(multiprocessing.Process):
def __init__(self):
"""
constructor for multiprocessing
"""
multiprocessing.Process.__init__(self)
self.__suspend = False
self.__exit = False
def run(self):
# Enter the code you wantrun 함수 부분에 원하는 multiprocessing 구현부를 작성해주시면 됩니다.
이 multiprocessing 함수는 python의 (Global Interpreter Lock)문제를 피해갈 수 있습니다.
대신에 프로세스간 변수를 공유하려면 또 다른 방법을 써야하는데요
그 방법은 다음에 다뤄보겠습니다.
'Python' 카테고리의 다른 글
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
|---|---|
| Flask socketIO simple usage and code (0) | 2018.02.14 |
| Pandas DataFrame를 csv로 저장하고 로드하기 (0) | 2017.11.12 |
| python BeautifulSoup 이용한 간단한 크롤링 (0) | 2017.11.12 |
| Anaconda Python package tool kit 간단한 사용법 (0) | 2017.11.08 |
Pandas DataFrame를 csv로 저장하고 로드하기
Pandas DataFrame에 저장된 데이터셋을 파일로 저장하고 로드하면 좋겠다는 생각이 들어서 여러모로 검색을
하여서 조금씩 정보를 찾았다.
일단 csv로 저장하는 방법이다. 매우 간단하다.
import pandas as pd
time_pd = pd.DataFrame(0., columns=col, index=time_range)
time_pd.to_csv("filename.csv", mode='w')일단 위의 소스는 time_pd라는 임의의 DataFrame을 생성한 뒤 바로 csv파일로 저장하는 소스코드이다.
mode에 인자값을 ‘a’ 로 해주면 덮어쓰기가 아닌 추가로 내용을 쓸 수 있다.
time_pd2.to_csv("filename.csv", mode='a', header=False)이렇게 하면 위에서 말한대로 추가가 되고 header를 False 값을 주면 추가되는 값에 header가 찍히지 않는다.
dataset = pd.read_csv("filename.csv", index_col=0)
print(dataset)반대로 csv파일을 불러오는 소스코드이다. 인덱스 column을 0번째 줄로 정하겠다는 의미이다.
참으로 유용하면서 간단한 모듈이라고 할 수 있겠다.
'Python' 카테고리의 다른 글
| Django 에서의 간단한 마이그레이션 과정 (0) | 2018.02.16 |
|---|---|
| Flask socketIO simple usage and code (0) | 2018.02.14 |
| python multiprocessing 사용하기 (1) | 2018.02.12 |
| python BeautifulSoup 이용한 간단한 크롤링 (0) | 2017.11.12 |
| Anaconda Python package tool kit 간단한 사용법 (0) | 2017.11.08 |
