Docker private registry 설치 및 사용법

안녕하세요 코코넛입니다.
이번에는 여러분들이 사용하는 docker image를 private하게 관리(image push, pull, docker auth 등)
할 수 있는 docker private registry를 Ubuntu linux에 설치하는 설치방법과
간단한 사용법을 다루겠습니다.
Ubuntu linux에 설치되어 있는 docker를 기준으로 설치를 진행하였습니다.
docker-compose를 사용하여 registry 설치를 진행하였으며,
아래의 docker-compose yaml파일 형식의 script를 이용하여 설치를 간단하고 빠르게 진행할 수 있습니다.
docker-compose.yml => 이 파일은 어느 위치에서 작성이 되어도 괜찮습니다
htpasswd => /auth 라는 디렉터리를 임의의 생성한 후에 auth 디렉터리 하위 경로에 위치합니다 예: /data/auth/htpasswd
docker 명령어를 통해 htpasswd 파일을 생성합니다.
docker run –entrypoint htpasswd registry:2.7.0 -Bbn test_realm_name test_passwd > /data/auth/htpasswd
위의 인증 파일까지 생성이 되었다면 아래의 명령어를 통해 생성한 docker-compose.yml 을 통해 docker registry를
컨테이너로 생성해 줍니다.
docker-compose.yml이 존재하는 경로 상에서 “docker-compose up -d” 라고 명령어를 실행해 줍니다.
그 다음 docker registry 컨테이너가 정상적으로 생성되었는지 컨테이너 리스트 명령어로 확인합니다.
docker ps | grep registry
컨테이너가 확인되었다면 registry 컨테이너가 생성이 된 것 입니다.
이제 생성된 docker private registry에 테스트할 겸 docker image를 push해 봅시다.
docker pull python:3.8
명령어로 python3.8 이미지를 docker hub에서 pull받아 줍니다.
그리고 생성한 docker private registry 에 login 아래의 명령어를 통해 로그인하여 줍니다.
docker login localhost:5000
위에서 생성한 realm과 passwd 를 입력하여 로그인합니다.
위에서 pull 받은 python3.8 이미지를 tag 명령어를 이용하여 생성한 registry에 push가 가능하도록 해줍니다.
docker tag python:3.8 localhost:5000/python:3.8
docker images 명령어를 통해 retag된 image와 tag하기 전의 이미지 2개를 확인할 수 있습니다.
생성한 registry에 아래의 명령어를 입력하여 push합니다.
docker push localhost:5000/python:3.8
위의 명령어로 성공적으로 docker private registry에 push가 되었다면
docker pull localhost:5000/python:3.8
명령어를 이용하여 image가 pull이 되는지 확인해 봅니다.
여기까지 간단한 docker private registry 설치 방법과 사용법이었습니다.
'Docker' 카테고리의 다른 글
| Docker의 기본적인 명령어 (0) | 2017.11.12 |
|---|
Dask 소개 및 자주 사용하는 함수
안녕하세요 coconut입니다.
이번에는 유명한 Pandas 외에 Dask라는 오픈소스를 소개합니다.
기존의 pandas는 읽어들이는 모든 데이터를 메모리에 적재하여, 연산하는 방식이어서 거대한 규모의 데이터를
pandas에 적재할 시에 메모리가 부족해 지는 이슈가 자주 발생하였습니다.
이러한 문제를 그나마 적은 메모리로 연산을 할 수 있는 오픈소스가 있으니 그것이 dask라는 오픈소스입니다.
dask는 거대한 데이터를 가상의 데이터프레임으로 형성합니다.
# 가상의 데이터프레임은 메모리에 모든 데이터를 적재하지 않습니다.

그렇다면 어떻게 데이터를 연산하느냐?
가상의 데이터프레임을 파티션(구역)으로 나누어 메모리에 순차적으로 올리고 내리어 연산을 하게 됩니다.
그렇게 때문에 대용량 데이터라도 그에 비해 적은 메모리로 처리가 가능합니다.
# csv file read
import dask.dataframe as dd
# S3 bucket direct access
import dask.dataframe as dd
위의 코드는 dask를 통해서 기본적으로 컴퓨터에 있는 csv데이터를 가져오는 방법과 아래에는 많이 사용하는 aws의 s3 버킷의 데이터를 dask를 통해서 가져올 수 있는
코드입니다.
(단 s3 버킷의 데이터는 pip install s3fs를 통해서 추가로 package를 설치해 줘야 합니다. aws의 credentials 도 셋팅되어 있어야 함.)
dask의 데이터프레임과 pandas의 데이터프레임은 같지 않습니다.
때문에 dask과 pandas간의 데이터프레임 전환을 할 수 있는 함수가 있습니다.
dask의 데이터프레임을 ddf, pandas의 데이터프레임을 df라 하겠습니다.
dask => pandas
df = ddf.compute()
pandas => dask
ddf = dd.from_pandas(df)
이러한 식으로 변환이 가능합니다.
dask의 여러가지 기능을 정확히 알고 사용하려면 문서를 참고할 수 있습니다. => https://dask.org/
제가 자주 이용하는 애트리뷰트 몇가지를 소개합니다.
dask.dataframe.read_csv => csv 형식 데이터를 읽어올 때
dask.dataframe.read_json => json 형식 데이터를 읽어올 때
dask.dataframe.assign => 기존의 데이터프레임을 함수를 통해 변형 후에 기존 데이터는 변형되지 않고 새로운 변수에 리턴함.
dask.dataframe.apply => 기존의 데이터프레임을 함수를 통해 변형 후에 기존 데이터가 변형되므로 기존의 데이터를 보증할 수 없음.
dask.dataframe.count => 유효한 데이터를 컬럼별로 count하여 표시하여 줍니다. count 후에 compute를 해야 연산이 실행됩니다.
dask.dataframe.dropna => nan인 데이터를 로우 혹은 컬럼별로 제거할 수 있습니다.
다른 개발자의 dask 설명글도 출처를 첨부합니다. => https://devtimes.com/python-dask/
위의 설명글을 보고 샘플 코드를 작성하여 보았습니다.
위의 개발자분이 설명한 글의 데이터를 다운받기 위해서
wget -O crime.csv https://data.cityofchicago.org/api/views/ijzp-q8t2/rows.csv?accessType=DOWNLOAD와 같은 명령어로 crime.csv 데이터셋을 다운받습니다.
아래의 코드는 이해를 돕기 위해 첨부합니다.
'Python' 카테고리의 다른 글
| 유용한 파이썬 문법(Useful Skill) (0) | 2020.02.24 |
|---|---|
| json to csv by python method call(파이썬으로 json을 csv 변환) (0) | 2019.09.06 |
| python으로 동영상 정보 확인하기(feat. PyAV) (0) | 2019.06.10 |
| Python list VS Numpy for matrix multiply (0) | 2019.06.10 |
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
윈도우 WSL2 설정 (포트포워딩, vmmem 이슈, 시작 프로그램 등)
안녕하세요, 코코넛입니다~!
이번에는 제가 애용하고 있는 윈도우 OS의 WSL2(Windows Subsystem for Linux version 2)에 관해
- 포트포워딩
- vmmem 이슈 => wsl2 에 자원 할당
- 윈도우 시작 시에 wsl2 내에서 원하는 bashscript 실행
이렇게 세가지를 다뤄 보도록 하겠습니다.
우선 1번 포트포워딩인데요, wsl2 내에서 외부로 포트포워딩하고 싶은 경우 방화벽 설정을 건드려 줘야 합니다.
아래의 스크립트를 원하는 file 이름으로 확장자명은 .ps1 형식으로 원하는 경로에 저장을 합니다. (예: port_fowarding.ps1)
$remoteport = bash.exe -c “ifconfig eth0 | grep ‘inet ‘”
$found = $remoteport -match ‘\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}’;
if( $found ){
$remoteport = $matches[0];
} else{
echo “The Script Exited, the ip address of WSL 2 cannot be found”;
exit;
}
#[Ports]
#All the ports you want to forward separated by comma
$ports_tcp=@(22,80,443,3306);
#[Static ip] #You can change the addr to your ip config to listen to a specific address
$addr=’0.0.0.0′;
$ports_a_tcp = $ports_tcp -join “,”;
#Remove Firewall Exception Rules
iex “Remove-NetFireWallRule -DisplayName ‘WSL 2 Firewall Unlock_TCP’ “;
#adding Exception Rules for inbound and outbound Rules
iex “New-NetFireWallRule -DisplayName ‘WSL 2 Firewall Unlock_TCP’ -Direction Outbound -LocalPort $ports_a_tcp -Action Allow -Protocol TCP”;
iex “New-NetFireWallRule -DisplayName ‘WSL 2 Firewall Unlock_TCP’ -Direction Inbound -LocalPort $ports_a_tcp -Action Allow -Protocol TCP”;
for( $i = 0; $i -lt $ports_tcp.length; $i++ ){
$port = $ports_tcp[$i];
iex “netsh interface portproxy delete v4tov4 listenport=$port listenaddress=$addr”;
iex “netsh interface portproxy add v4tov4 listenport=$port listenaddress=$addr connectport=$port connectaddress=$remoteport”;
}
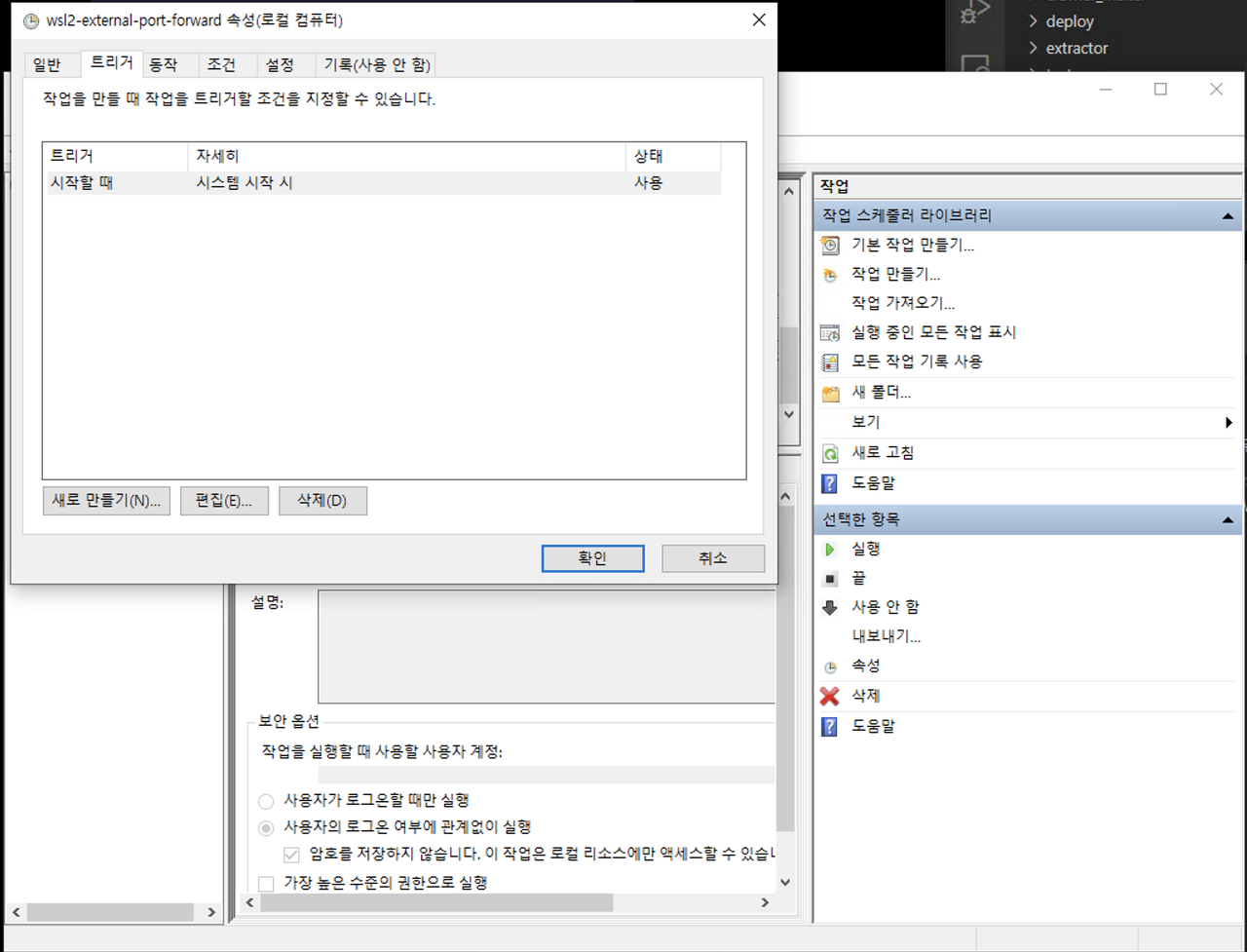
그리고 윈도우의 ‘작업 스케쥴러’ 라고 검색해서 작업 스케쥴러 상에서 작업 만들기를 통해서 이 파일을 윈도우가 시작할 때 실행되도록 할텐데요,
트리거 => 시스템 시작 시 로 설정을 해줍니다.
동작탭에서
프로그램 / 스크립트 => C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe
시작 위치 => 위의 스크립트가 존재하는 폴더 Path (예: C:\Users\test\wsl2_config)
인수 추가 => -ExecutionPolicy Bypass -File .\port_fowarding.ps1
라고 설정해 줍니다.
그리고 저장을 해줍니다.
여기까지 하면 포트포워딩까지는 됩니다.
두번째는 윈도우 cpu, memory 등을 wsl2에 임의로 할당하는 설정입니다.
wsl2에 임의로 자원을 할당하지 않으면 윈도우에서 사용하는 메모리를
버퍼 상태로 할당하여 윈도우에서 필요할 때 메모리를 사용을 못할 수 있습니다.
그래서 자원을 임의로 할당해 주면 이런 불상사는 일어나지 않겠죠?
아래의 스크립트를 C:\Users\사용자명\.wslconfig 로 저장합니다.
꼭 사용자 홈 디렉터리에 .wslconfig 의 이름으로 저장이 되어야 윈도우에서 인식할 수 있습니다.
[wsl2] memory=4GB
processors=2
swap=2GB
localhostForwarding=true
memory는 4GB를 할당, cpu 프로세서는 2개, 스왑메모리는 2GB를 할당하는 옵션입니다.
memory를 할당하지 않을 경우 윈도우 메모리 자원을 wsl2가 점유하고 있을 수 있으니 주의바랍니다.
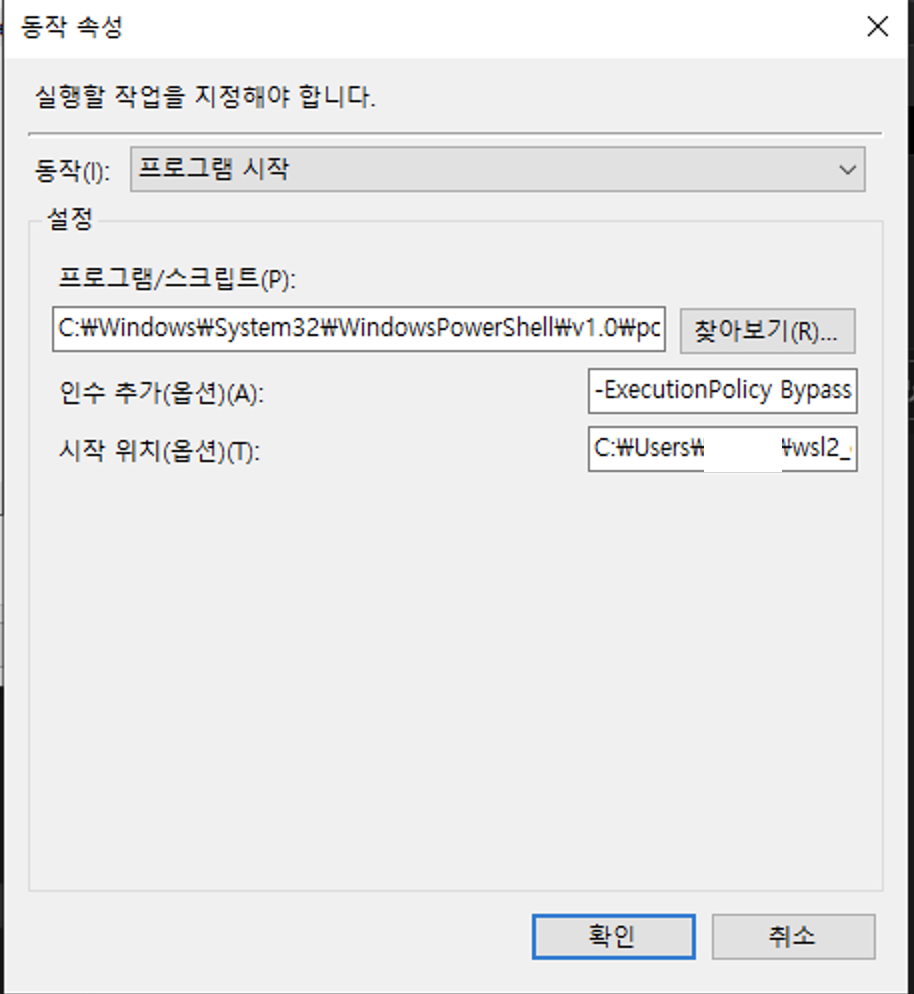
마지막으로 윈도우가 구동되면서 작업 스케쥴러를 통해서 wsl2내의 bashscript를 구동시켜 원하는 프로세스를 실행시킬 수 있는 설정입니다.
아래의 스크립트를 파일로 임의의 이름으로 확장자는 .bat 형식으로 원하는 경로에 저장을 해줍니다. (예: init_system.bat)
C:\Windows\System32\bash.exe -c “/home/wsl2유저명/init_system.sh”
그리고 저장한 파일을 또 ‘작업 스케쥴러’ 에 추가해 줍니다.
트리거 => 시스템 시작 시 로 설정을 해줍니다.
이번에는 동작탭에서
프로그램 / 스크립트 => C:\Users\test\wsl2_config\init_system.bat
정도로 설정을 해주면 됩니다. 이 설정은 /home/wsl2유저명/init_system.sh 를 윈도우 시작 시에 실행하게 됩니다.
용도의 예로는 crontab 이나 webserver 를 구동시키는 정도를 나열해 볼 수 있겠습니다.
'etc' 카테고리의 다른 글
| 우분투에 turn server 구축하기 (2) | 2019.01.27 |
|---|---|
| wakeonlan use by terminal(wol 리눅스에서 사용하기) (0) | 2018.04.10 |
| fortran 컴파일하고 사용하기 (0) | 2017.11.17 |
Bootstrap modal 혹은 Bootstrap Vue modal 에서 키보드 핸들링이 안될 때
안녕하세요 coconut 입니다~
이번에는 웹페이지에서 흔하게 사용하는 modal 내에서 가끔 쓰일 수 있는 이벤트인 Ctrl + C 와 같은 키보드 핸들링을
가능하게 해주는 옵션을 알아보겠습니다.
저는 당연하다고 생각했던 modal 내에서 클립보드 복사가 안되는 문제를 발견했습니다.
답답해서 여러가지 키워드로 구글링을 하다가 원인을 겨우겨우 발견하게 되었습니다.
modal이 create 되면 modal 창이 유지되도록 강제로 포커싱하는 이유였습니다.
$.fn.modal.Constructor.prototype._enforceFocus = function() {};
bootstrap4 기준 이 코드로 해결을 해줄 수 있습니다.
bootstrap vue 기준으로는 b-modal 생성 시에 no-enforce-focus 옵션을 넣으면 해결이 되는 문제입니다.

여기서 핵심은 사용하는 프레임워크 혹은 언어에서 강제 포커싱을 해제해주면 됩니다.
즐거운 코딩하시기 바랍니다~
2020년 가을 제주도 나홀로 여행 기록(숙박, 카페, 느낌, 일)
2020년말 나는 비즈니스 겸 휴가로 제주도를 찾았다.
비수기에다가 항공권 가격도 매우 착해서 지갑에서 돈이 덜 나갔다.
또한 나는 11박을 서귀포시에 있는 슬로시티란 게스트하우스에다가 예약을 하였다.

11박에 약 18만원에 예약하여서 너무 싸서 방이 조금 안 좋을거라는 생각을 했지만 체크인 해보니 사장님이 친절하셨고, 매일 청결하게 청소를 해주셔서
괜찮았다. 거기다가 간단한 조식을 무료로 주고 하니 아침마다 가볍게 먹고 나갈 수 있어서 좋았다.
제주도로 들어오고 3 ~ 4일간은 클라이언트와 계속 연락하고 미팅하면서 일을 하고 카페에서도 바깥 분위기와 느낌을 받으면서 일을 겸사겸사 해주었다.
5일째 일이 어느 정도 협의가 되고 진행이 되어서 바깥에 조금씩 둘러보고 성산일출봉도 찾아서 나홀로 셀카를 많이 찍었다.
후에 내가 사진 찍은 것들을 살펴보니 사진도 많이 찍고 하는 사람이 잘 찍는 것 같았다.

성산일출봉
표정이 어색하다 ㅋ
제주도에서 대부분의 시간을 카페를 돌아다니며 컴터를 하면서 시간을 보냈는데 와닿았던 카페 몇 곳을 소개하자면 서귀포시 중심쪽에 있는
블루하우스 카페와 서귀포시가지에서 약간 서쪽의 내리막길로 가면 코너에 숨겨져 있는 서홍정원이 괜찬은 것 같다.
이 두 곳의 카페를 괜찬게 생각한 기준은 첫째로 느낌과 분위기이다. 블루하우스는 도심지에서 자기가 하고 싶은 일을 하면서 커피를 여유롭게 맛보는 느낌?
이고 두번째 서홍정원은 개인적인 생각으로는 서귀포시 주변의 카페중에서는 제일 느낌이 평화롭고 여유가 느껴지며, 심신이 안정되는 카페였다.
두 카페 모두 커피와 음식은 모두 맛있었으며, 주변 경치와 분위기가 매우 좋았다.


위의 사진은 서홍정원 안에서 셀카~
블루하우스는 내부 인테리어가 고급스럽고 돈이 많이 들어간 느낌이며, 서홍정원은 내부 인테리어도 좋고, 밖의 풍경 및 분위기 등 안팎의 환경 모두 좋았다.
암튼 카페 얘기는 여기까지하고 몇 일 게스트하우스에서 지내다가 저녁이 되면 게스트하우스의 다른 사람들과 자연스럽게 얘기를 하게 되었는데,
3 ~ 4일인지 저녁에 붙임성 좋으신 남자분이 합석해서 얘기하자고 사람들을 모았다.
그 분은 정말 사람에게 붙임성이 매우 좋았고, 말도 재치있게 매우 잘하셔서 재미있는 대화를 많이 나눴다.

천제연폭포 제1폭포
그리고 웃긴 건 제주도 어딜가도 스타벅스가 없는 곳이 없었다. 미래에 만약 달기지가 생긴다면 스타벅스가 제일 먼저 생기지 않을까? 이런 생각도 했다.
'life' 카테고리의 다른 글
| 메모의 힘 (0) | 2019.11.05 |
|---|---|
| (초)미세먼지 마스크 2종 비교 (0) | 2018.03.29 |
유용한 파이썬 문법(Useful Skill)
안녕하세요 개발자 코코넛입니다. 새해가 지나고 처음으로 글을 쓰네요.
이번에는 파이썬을 쓰면서 유용하다고 생각되는 파이썬의 문법? 스킬들을
기록할 겸 정리해 보았습니다.
- 컴프리헨션
이 기술은 알고 나서 정말 즐겨 사용하는 문법입니다.
시각적으로는 구조가 간단한 for루프를 한줄로 축약하여 표현할 수 있는데요,
그리고 기본 for 루프보다 속도도 더 빠르다고 합니다.
예) 리스트 컴프리헨션
import time
ex_list = 1000000
# for loop
result = []
start_time = time.time()
for e in range(ex_list):
result.append(e)
duration_time = time.time() - start_time
print("for loop : " + str(duration_time))
# comprehension
start_time = time.time()
result = [e for e in range(ex_list)]
duration_time = time.time() - start_time
print("comprehension : " + str(duration_time))# 실행한 화면

백만번 기준으로 리스트를 채울 경우 거의 2배의 속도 차이가 납니다.
예) 딕셔너리 컴프리헨션
import time
ex_list = 1000000
# for loop
result = {}
start_time = time.time()
for e in range(ex_list):
result[str(e)] = e
duration_time = time.time() - start_time
print("for loop : " + str(duration_time))
# comprehension
start_time = time.time()
result = {str(e): e for e in range(ex_list)}
duration_time = time.time() - start_time
print("comprehension : " + str(duration_time))# 실행한 화면

딕셔너리는 근소한 차이로 속도가 차이가 납니다.
이와 같이 컴프리헨션은 코드의 간결함과 속도를 살려줍니다.
하지만 위에 있는 1차 표현식 정도는 괜찬지만
result = [y for y in [x for x in range(ex_list)]]
이러한 2차 이상의 표현식은 코드의 가독성이 떨어지므로
2차 이상의 표현식을 컴프리헨션에 적용하는 것은 피하라고 권고합니다.
- multiprocessing 모듈
이 모듈은 파이썬의 GIL(Global Interpreter Lock)의 문제를 가진 병렬 기반 threading 모듈을
우회?해서 대용하여 사용할 수 있는 모듈입니다. 말 그대로 멀티프로세싱이기에 메모리가 공유되지는 않습니다.
저는 주로 병렬로 처리할 작업들을 한 리스트에 모아서 다수의 프로세스에 균등 분할하여 실행하는 것을 좋아합니다.
proc_list = []
workers = 8
for wk in range(workers):
front = int(len(tasks) * (wk / workers))
rear = int(len(tasks) * ((wk + 1) / workers))
proc = Process(target=func_name, args=(tasks[front:rear],))
proc_list.append(proc)
for proc in proc_list:
proc.start()
for proc in proc_list:
proc.join()
이러한 식으로 코드를 생성하면 프로세스 8개에 작업을 균등하게 분할하여
병렬로 실행할 수 있는 것이죠.
참고로 proc.join()은 모든 프로세스가 종료될 때까지 기다리는 역할을 합니다.
여기까지 간단하게 2가지 제가 사용하는 유용한 스킬? 정도를 끄적여 보았습니다.
다음에는 파이썬의 비동기 실행 모듈인 asyncio 에 대해서 기록해 보려고 합니다.
여기까지~
'Python' 카테고리의 다른 글
| Dask 소개 및 자주 사용하는 함수 (0) | 2022.04.23 |
|---|---|
| json to csv by python method call(파이썬으로 json을 csv 변환) (0) | 2019.09.06 |
| python으로 동영상 정보 확인하기(feat. PyAV) (0) | 2019.06.10 |
| Python list VS Numpy for matrix multiply (0) | 2019.06.10 |
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
이 글을 쓰는 이유는 내 개인적인 메모에 대한 생각을 블로그에 남기고자 쓴다.
글을 어찌해서 보게 된 분들에게 도움이 되었으면 좋겠다.
일단 내가 메모를 쓰는 이유는 이러하다.
인생을 살면서 생산되는 정보량은 엄청나고, 나는 그것들을 절대 다 이해하지 못할 뿐 더러
나에게 필요한 정보만 기억하기도 어렵다(당연히 계속 상기시키지 않는 이상 망각하기 때문에)
그래서 내 개인적인 생각으로는 암기가 필요하지 않으면서 중요도가 덜하고 응용이 필요하지 않은
단문 또는 장문의 데이터는 메모하는 것이 좋다고 생각한다.
2019년 11월 5일 현재 메모앱인 에버노트를 적극적으로 써온지가 3년이 지났다.
처음에는 대학생 시절인 2014년부터 2015년까지는 간편한 구글의 Keep을 사용하였으나
에버노트의 많은 기능에 반해서 현재 3년 넘게 사용하고 있는 중이다.
아무튼 메모의 장점은 이루말할 수 없을 정도로 많은 것 같다.
내가 생각하는 메모의 종류는 크게 두 종류라고 생각한다.
- 수기로 작성하는 아날로그 메모
- 컴퓨터나 디지털기기로 작성하는 디지털 메모
두 가지 방식의 메모는 서로의 단점을 보완해 주는 장점이 있고 하니 따라서 두가지 메모는 상황에 따라서
이용하는 것이 좋다고 생각한다.
- 수기로 작성하는 메모 – 일상 생활에서 아주 흔한 메모방식이긴 하나 쓰는 사람에 따라서 가독성에 차이가 있고, 내용이 장문이 될 경우 보기가 힘들어 진다. 따라서 저는 아날로그 메모를 할 때는 다른 사람의 이야기나 내용을 보고 핵심이 되는 키워드만 적어 놓고, 이해가 어려우면 간단한 모식도? 혹은 그림으로 표현을 하여 나중에 기억을 할 수 있도록 한다.
- 디지털 메모 – 내 개인적인 생각으로는 나는 세상이 한창 디지털화가 되어가는 좋은 시대에 태어났다고 생각한다. 만약 조선시대에 태어 났다면 나는 농사나 짓고 있을지도 모른다… 아무튼 디지털 메모의 장점은 단문이던 장문이던 그림이건 사진이건 그대로 저장할 수 있다는 점이다. 그리고 또 편리하기도 하다. 스크래핑을 해도 몇초가 걸리지 않는다. 이러한 디지털 메모의 장점은 거의 무한하다고 생각이 된다. 현재 우리 세계에서 전자기기의 저장용량은 엄청나다. 텍스트로 24시간 365일 평생 해도 자신의 컴퓨터 하드디스크를 절대로 다 채울 수 없을 것이다. 이러한 저장 공간의 장점 외에도 빠른 작성, 복사 붙여넣기 등이 있지만 제일 큰 장점이라고 생각하는 것은 색인 기능이다. 아날로그와 비교해서 수만 개의 메모에서 하나의 메모를 찾거나 혹은 몇개의 메모를 찾을 때 디지털 메모는 시간이 얼마 걸리지 않아 다 찾아 준다.
그래서 나는 메모하는 것을 추천한다. 특히 디지털 시대에 메모앱은 정말 좋은 것 같다.
메모앱 중에 알고 있는 것을 보자면
구글 Keep, – UX가 심플하고 간단한 내용들을 다루기에 좋다.
에버노트 – 많은 기능(웹스크래핑 기능은 정말 좋다고 생각)을 지원하고, 연동되는 앱들이 많다. 플랫폼 또한 넓어서 괜찬다고 생각한다.
딱 2가지 추천한다. 왜냐하면 이 두가지만 써보았다;;
나는 에버노트를 카테고리를 나누어 사용한다.
예를 들어 / 자기개발 / 아이디어 / 기록 / 업무 / 개인 / 이런식으로 카테고리를 나눈 뒤
카테고리에 맞게 메모를 하면서 사용을 하고 있다. 이렇게 하면 카테고리별로 메모를 볼 수도 있으며,
관리하기도 편하다~
'life' 카테고리의 다른 글
| 2020년 가을 제주도 나홀로 여행 기록(숙박, 카페, 느낌, 일) (0) | 2020.10.11 |
|---|---|
| (초)미세먼지 마스크 2종 비교 (0) | 2018.03.29 |
json to csv by python method call(파이썬으로 json을 csv 변환)
안녕하세요. 이번에는 간단하게 nested json 포맷 데이터를 csv로 변환하는 코드를
여러분께 공유해 드리려고 합니다.
전체 코드부터 공유하겠습니다.
# -*- coding: utf-8 -*-
import json
import glob
from traceback import format_exc
from multiprocessing import Process
workers = 10
def iterdict(d, seq, fc):
for k,v in d.items():
if isinstance(v, dict):
iterdict(v, seq + "/" + k, fc)
elif isinstance(v, list):
for e in v:
iterdict(e, seq + "/" + k, fc)
else:
print(seq + "/" + k + ", " + str(v).replace("\n", '\\n'))
fc.write(seq + "/" + k + ", " + str(v).replace("\n", '\\n') + "\n")
def multi_proc(json_data_list, output_path):
for json_name, json_data in json_data_list:
save_path = output_path + "/" + json_name + ".csv"
fc = open(save_path, "a")
fc.write("key, value\n")
iterdict(json_data, "data", fc)
fc.close()
# 메인 메서드
def main_convert(input_json_path, output_path):
# json 파일들이 존재하는 경로의 모든 파일을 가져옴
json_path = glob.glob(input_json_path + "/*")
json_data_list = []
for each_path in json_path:
each_json_name = each_path.split("/")[-1].split(".")[0]
f = open(each_path, "r")
json_data = {}
try:
json_data = json.loads(f.read())
except:
print(format_exc())
f.close()
json_data_list.append([each_json_name, json_data])
proc_list = []
for wk in range(workers):
front = int(len(json_data_list) * (wk / workers))
rear = int(len(json_data_list) * ((wk + 1) / workers))
proc = Process(target=multi_proc, args=(json_data_list[front:rear], output_path,))
proc_list.append(proc)
for proc in proc_list:
proc.start()
for proc in proc_list:
proc.join()
사용 방법을 먼저 소개하겠습니다
여러분이 사용하는 코드에 main_convert() 메서드를 호출합니다.
메서드안에 두개의 파라미터를 입력합니다.(json file path, csv output path)
그리고 실행시키면 됩니다.
그리고 간단하게 코드를 리뷰하겠습니다.
먼저 main_convert 메서드에서 glob 내장함수를 통해 지정한 경로내에서 모든 파일을 불러옵니다.
불러온 파일들을 모둘 읽어들여서 json_data_list에 할당합니다.
그리고 코드의 상단에서 지정한 workers의 수만큼 프로세스를 데이터를 태워서 다수의 json 파일이 csv로
프로세스 개수의 비례한 속도로 변환이 되게 됩니다.
multi_proc() 메서드는 iterdict()메서드에 각각의 json을 파싱시켜 csv로 저장시키는 역할을 합니다.
여기까지 간단한 코드 소개를 마치겠습니다.
'Python' 카테고리의 다른 글
| Dask 소개 및 자주 사용하는 함수 (0) | 2022.04.23 |
|---|---|
| 유용한 파이썬 문법(Useful Skill) (0) | 2020.02.24 |
| python으로 동영상 정보 확인하기(feat. PyAV) (0) | 2019.06.10 |
| Python list VS Numpy for matrix multiply (0) | 2019.06.10 |
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
BERT 한국어버전(korquad) training 및 evaluating 해보기
안녕하세요 coconut입니다. 오랜만에 BERT에 관해 포스팅을 하게 되었습니다.
BERT(Bidirectional Encoder Representations from Transformers)는 구글에서 배포한 오픈 소스입니다.
BERT 전에는 NLP 알고리즘으로 높은 퍼포먼스를 자랑하던 ensemble 기법이 있었는데요.
BERT가 Release되고, 많은 분들이 시도를 해보시고 인기도 좋아서 저도 시도를 해보았는데요,
BERT를 한글 기준으로 돌릴 수 있도록 LG CNS에서 데이터를 제공하였는데요, https://korquad.github.io/ 에서
데이터를 확인하실 수 있습니다.
우선 https://github.com/google-research/bert 에 접속하여 bert 오픈소스를 받아 줍니다. 혹은
git clone https://github.com/google-research/bert.git 으로 받으셔도 됩니다.

그리고 fine tuning이 제외된 초기 상태로 진행할 거라면 BERT-Base, Multilingual Cased (New, recommended) 파일도
받아줍니다.
받은 파일을 압축을 풀고 directory 하나를 생성하여 그 안에 넣어줍니다.(저는 pretrained 라고 하였습니다.)
그리고 위의 https://korquad.github.io/ 에 접속하여 Training set 과 Dev set 그리고 evaluating 하기 위해
Evaluation script를 받아 줍니다.
그럼 총 세 개의 파일을 받을 수 있는데요
KorQuAD_v1.0_train.json
KorQuAD_v1.0_dev.json
evaluate-v1.0.py
요 세개를 받으시면 됩니다.
아까 생성한 directory 에 이 파일들도 넣어주셔도 되고, 아니면 그냥 따로 다른 directory 에 넣어주셔도 됩니다.(korquad라고 설정하였습니다.)
이제 tensorflow_gpu 버전이 설치된 서버에서 training을 시켜줍니다.
python run_squad.py –bert_config_file=pretrained/bert_config.json –vocab_file=pretrained/vocab.txt –output_dir=output –do_train=True –train_file=korquad/KorQuAD_v1.0_train.json –do_predict=True –predict_file=korquad/KorQuAD_v1.0_dev.json –do_lower_case=false –num_train_epochs=3.0 –max_seq_length=128 –train_batch_size=32 –init_checkpoint=pretrained/bert_model.ckpt
위의 스크립트대로 실행하였으나 Out Of Memory 이슈로 실행을 하지 못하여 적당히 조절하면서 테스트를 진행하였습니다.
아래는 메모리가 12기가인 GPU 기준으로 max_seq_length와 train_batch_size를 정리하여 놓은 표입니다.

몇 시간 뒤에 training이 끝나면 output 디렉터리에 predictions.json 과 training model 파일들이 생성이 되어 있습니다.
python evaluate-v1.0.py KorQuAD_v1.0_dev.json predictions.json 을 하여 evaluating을 할 수 있습니다.
여기까지 마치겠습니다.
'DeepLearning' 카테고리의 다른 글
| 간단하게 보는 CPU와 GPU의 연산 차이 (0) | 2018.03.29 |
|---|---|
| Python 딥러닝 관련 간단한 활성화 함수 (0) | 2018.02.20 |
python으로 동영상 정보 확인하기(feat. PyAV)
안녕하세요 coconut입니다. 회사일을 진행하던 중 작업에 동영상 정보를 확인할 일이 생겨서 python으로 동영상을 읽어서 정보를 열람하는 것을 포스팅하게 되었습니다.
우선 동영상을 읽어올 수 있는 여러가지 파이썬 패키지 중에서 저는 PyAV를 선택하여 작업을 해보았습니다.
pip install av설치는 위와 같이 해주면 됩니다.
설치가 안될 시에는 로그를 확인하여 아래와 같이 install dependency를 해결해 준 뒤에 설치를 해줍니다.
case of MacOS
brew install ffmpeg pkg-config
case of Ubuntu >= 18.04 LTS
# General dependencies sudo apt-get install -y python-dev pkg-config
# Library components sudo apt-get install -y \
libavformat-dev libavcodec-dev libavdevice-dev \
libavutil-dev libswscale-dev libswresample-dev libavfilter-dev
case of Ubuntu < 18.04 LTS
sudo apt install \
autoconf \
automake \
build-essential \
cmake \
libass-dev \
libfreetype6-dev \
libjpeg-dev \
libtheora-dev \
libtool \
libvorbis-dev \
libx264-dev \
pkg-config \
wget \
yasm \
zlib1g-dev
wget http://ffmpeg.org/releases/ffmpeg-3.2.tar.bz2 tar -xjf ffmpeg-3.2.tar.bz2 cd ffmpeg-3.2
./configure --disable-static --enable-shared --disable-doc
make
sudo make install
case of windows
https://ffmpeg.zeranoe.com/builds/
를 통하여 설치 후 PyAV를 설치합니다.
설치가 끝나면 제가 테스트 했던 코드를 사용하여 설명을 하겠습니다.
import av # PyAV 임포트
from PIL import Image # Pillow 임포트
# 동영상을 임포트
container = av.open('동영상이름.mp4')
video = container.streams.video[0]
frames = container.decode(video=0)
# 프레임 단위로 동영상에서 이미지 추출
for frame in frames:
frame.to_image().save('frame-%04d.jpg' % frame.index)
# 이미지 하나 추출 뒤 포문 탈출
break
# 동영상 재생시간
time_base = video.time_base
# fps 샘플링 추출
fps = video.average_rate
print(time_base)
print(container.duration)
# 동영상 총 프레임
print(video.frames)
# 초당 프레임 계산
fps_calculate = int(str(fps).split('/')[0]) / int(str(fps).split('/')[1])
print("fps : " + str(fps_calculate))
print("movie seconds : " + str(int(video.frames) / fps_calculate))
# 동영상에서 추출한 이미지의 해상도 계산
im = Image.open('frame-0000.jpg')
width, height = im.size
print("width : " + str(width))
print("height : " + str(height))
코드상의 주석으로 설명이 가능합니다.
fps : Frames Per Second (초당 프레임 개수입니다.) – 보통 30fps
여기까지 간단하게 다뤄 보았습니다. 끝~!
'Python' 카테고리의 다른 글
| 유용한 파이썬 문법(Useful Skill) (0) | 2020.02.24 |
|---|---|
| json to csv by python method call(파이썬으로 json을 csv 변환) (0) | 2019.09.06 |
| Python list VS Numpy for matrix multiply (0) | 2019.06.10 |
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
| Python을 이용한 엑셀 읽기 및 쓰기(xlrd, xlwt) (0) | 2019.06.10 |
