Dask 소개 및 자주 사용하는 함수
안녕하세요 coconut입니다.
이번에는 유명한 Pandas 외에 Dask라는 오픈소스를 소개합니다.
기존의 pandas는 읽어들이는 모든 데이터를 메모리에 적재하여, 연산하는 방식이어서 거대한 규모의 데이터를
pandas에 적재할 시에 메모리가 부족해 지는 이슈가 자주 발생하였습니다.
이러한 문제를 그나마 적은 메모리로 연산을 할 수 있는 오픈소스가 있으니 그것이 dask라는 오픈소스입니다.
dask는 거대한 데이터를 가상의 데이터프레임으로 형성합니다.
# 가상의 데이터프레임은 메모리에 모든 데이터를 적재하지 않습니다.

그렇다면 어떻게 데이터를 연산하느냐?
가상의 데이터프레임을 파티션(구역)으로 나누어 메모리에 순차적으로 올리고 내리어 연산을 하게 됩니다.
그렇게 때문에 대용량 데이터라도 그에 비해 적은 메모리로 처리가 가능합니다.
# csv file read
import dask.dataframe as dd
# S3 bucket direct access
import dask.dataframe as dd
위의 코드는 dask를 통해서 기본적으로 컴퓨터에 있는 csv데이터를 가져오는 방법과 아래에는 많이 사용하는 aws의 s3 버킷의 데이터를 dask를 통해서 가져올 수 있는
코드입니다.
(단 s3 버킷의 데이터는 pip install s3fs를 통해서 추가로 package를 설치해 줘야 합니다. aws의 credentials 도 셋팅되어 있어야 함.)
dask의 데이터프레임과 pandas의 데이터프레임은 같지 않습니다.
때문에 dask과 pandas간의 데이터프레임 전환을 할 수 있는 함수가 있습니다.
dask의 데이터프레임을 ddf, pandas의 데이터프레임을 df라 하겠습니다.
dask => pandas
df = ddf.compute()
pandas => dask
ddf = dd.from_pandas(df)
이러한 식으로 변환이 가능합니다.
dask의 여러가지 기능을 정확히 알고 사용하려면 문서를 참고할 수 있습니다. => https://dask.org/
제가 자주 이용하는 애트리뷰트 몇가지를 소개합니다.
dask.dataframe.read_csv => csv 형식 데이터를 읽어올 때
dask.dataframe.read_json => json 형식 데이터를 읽어올 때
dask.dataframe.assign => 기존의 데이터프레임을 함수를 통해 변형 후에 기존 데이터는 변형되지 않고 새로운 변수에 리턴함.
dask.dataframe.apply => 기존의 데이터프레임을 함수를 통해 변형 후에 기존 데이터가 변형되므로 기존의 데이터를 보증할 수 없음.
dask.dataframe.count => 유효한 데이터를 컬럼별로 count하여 표시하여 줍니다. count 후에 compute를 해야 연산이 실행됩니다.
dask.dataframe.dropna => nan인 데이터를 로우 혹은 컬럼별로 제거할 수 있습니다.
다른 개발자의 dask 설명글도 출처를 첨부합니다. => https://devtimes.com/python-dask/
위의 설명글을 보고 샘플 코드를 작성하여 보았습니다.
위의 개발자분이 설명한 글의 데이터를 다운받기 위해서
wget -O crime.csv https://data.cityofchicago.org/api/views/ijzp-q8t2/rows.csv?accessType=DOWNLOAD와 같은 명령어로 crime.csv 데이터셋을 다운받습니다.
아래의 코드는 이해를 돕기 위해 첨부합니다.
'Python' 카테고리의 다른 글
| 유용한 파이썬 문법(Useful Skill) (0) | 2020.02.24 |
|---|---|
| json to csv by python method call(파이썬으로 json을 csv 변환) (0) | 2019.09.06 |
| python으로 동영상 정보 확인하기(feat. PyAV) (0) | 2019.06.10 |
| Python list VS Numpy for matrix multiply (0) | 2019.06.10 |
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
유용한 파이썬 문법(Useful Skill)
안녕하세요 개발자 코코넛입니다. 새해가 지나고 처음으로 글을 쓰네요.
이번에는 파이썬을 쓰면서 유용하다고 생각되는 파이썬의 문법? 스킬들을
기록할 겸 정리해 보았습니다.
- 컴프리헨션
이 기술은 알고 나서 정말 즐겨 사용하는 문법입니다.
시각적으로는 구조가 간단한 for루프를 한줄로 축약하여 표현할 수 있는데요,
그리고 기본 for 루프보다 속도도 더 빠르다고 합니다.
예) 리스트 컴프리헨션
import time
ex_list = 1000000
# for loop
result = []
start_time = time.time()
for e in range(ex_list):
result.append(e)
duration_time = time.time() - start_time
print("for loop : " + str(duration_time))
# comprehension
start_time = time.time()
result = [e for e in range(ex_list)]
duration_time = time.time() - start_time
print("comprehension : " + str(duration_time))# 실행한 화면

백만번 기준으로 리스트를 채울 경우 거의 2배의 속도 차이가 납니다.
예) 딕셔너리 컴프리헨션
import time
ex_list = 1000000
# for loop
result = {}
start_time = time.time()
for e in range(ex_list):
result[str(e)] = e
duration_time = time.time() - start_time
print("for loop : " + str(duration_time))
# comprehension
start_time = time.time()
result = {str(e): e for e in range(ex_list)}
duration_time = time.time() - start_time
print("comprehension : " + str(duration_time))# 실행한 화면

딕셔너리는 근소한 차이로 속도가 차이가 납니다.
이와 같이 컴프리헨션은 코드의 간결함과 속도를 살려줍니다.
하지만 위에 있는 1차 표현식 정도는 괜찬지만
result = [y for y in [x for x in range(ex_list)]]
이러한 2차 이상의 표현식은 코드의 가독성이 떨어지므로
2차 이상의 표현식을 컴프리헨션에 적용하는 것은 피하라고 권고합니다.
- multiprocessing 모듈
이 모듈은 파이썬의 GIL(Global Interpreter Lock)의 문제를 가진 병렬 기반 threading 모듈을
우회?해서 대용하여 사용할 수 있는 모듈입니다. 말 그대로 멀티프로세싱이기에 메모리가 공유되지는 않습니다.
저는 주로 병렬로 처리할 작업들을 한 리스트에 모아서 다수의 프로세스에 균등 분할하여 실행하는 것을 좋아합니다.
proc_list = []
workers = 8
for wk in range(workers):
front = int(len(tasks) * (wk / workers))
rear = int(len(tasks) * ((wk + 1) / workers))
proc = Process(target=func_name, args=(tasks[front:rear],))
proc_list.append(proc)
for proc in proc_list:
proc.start()
for proc in proc_list:
proc.join()
이러한 식으로 코드를 생성하면 프로세스 8개에 작업을 균등하게 분할하여
병렬로 실행할 수 있는 것이죠.
참고로 proc.join()은 모든 프로세스가 종료될 때까지 기다리는 역할을 합니다.
여기까지 간단하게 2가지 제가 사용하는 유용한 스킬? 정도를 끄적여 보았습니다.
다음에는 파이썬의 비동기 실행 모듈인 asyncio 에 대해서 기록해 보려고 합니다.
여기까지~
'Python' 카테고리의 다른 글
| Dask 소개 및 자주 사용하는 함수 (0) | 2022.04.23 |
|---|---|
| json to csv by python method call(파이썬으로 json을 csv 변환) (0) | 2019.09.06 |
| python으로 동영상 정보 확인하기(feat. PyAV) (0) | 2019.06.10 |
| Python list VS Numpy for matrix multiply (0) | 2019.06.10 |
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
json to csv by python method call(파이썬으로 json을 csv 변환)
안녕하세요. 이번에는 간단하게 nested json 포맷 데이터를 csv로 변환하는 코드를
여러분께 공유해 드리려고 합니다.
전체 코드부터 공유하겠습니다.
# -*- coding: utf-8 -*-
import json
import glob
from traceback import format_exc
from multiprocessing import Process
workers = 10
def iterdict(d, seq, fc):
for k,v in d.items():
if isinstance(v, dict):
iterdict(v, seq + "/" + k, fc)
elif isinstance(v, list):
for e in v:
iterdict(e, seq + "/" + k, fc)
else:
print(seq + "/" + k + ", " + str(v).replace("\n", '\\n'))
fc.write(seq + "/" + k + ", " + str(v).replace("\n", '\\n') + "\n")
def multi_proc(json_data_list, output_path):
for json_name, json_data in json_data_list:
save_path = output_path + "/" + json_name + ".csv"
fc = open(save_path, "a")
fc.write("key, value\n")
iterdict(json_data, "data", fc)
fc.close()
# 메인 메서드
def main_convert(input_json_path, output_path):
# json 파일들이 존재하는 경로의 모든 파일을 가져옴
json_path = glob.glob(input_json_path + "/*")
json_data_list = []
for each_path in json_path:
each_json_name = each_path.split("/")[-1].split(".")[0]
f = open(each_path, "r")
json_data = {}
try:
json_data = json.loads(f.read())
except:
print(format_exc())
f.close()
json_data_list.append([each_json_name, json_data])
proc_list = []
for wk in range(workers):
front = int(len(json_data_list) * (wk / workers))
rear = int(len(json_data_list) * ((wk + 1) / workers))
proc = Process(target=multi_proc, args=(json_data_list[front:rear], output_path,))
proc_list.append(proc)
for proc in proc_list:
proc.start()
for proc in proc_list:
proc.join()
사용 방법을 먼저 소개하겠습니다
여러분이 사용하는 코드에 main_convert() 메서드를 호출합니다.
메서드안에 두개의 파라미터를 입력합니다.(json file path, csv output path)
그리고 실행시키면 됩니다.
그리고 간단하게 코드를 리뷰하겠습니다.
먼저 main_convert 메서드에서 glob 내장함수를 통해 지정한 경로내에서 모든 파일을 불러옵니다.
불러온 파일들을 모둘 읽어들여서 json_data_list에 할당합니다.
그리고 코드의 상단에서 지정한 workers의 수만큼 프로세스를 데이터를 태워서 다수의 json 파일이 csv로
프로세스 개수의 비례한 속도로 변환이 되게 됩니다.
multi_proc() 메서드는 iterdict()메서드에 각각의 json을 파싱시켜 csv로 저장시키는 역할을 합니다.
여기까지 간단한 코드 소개를 마치겠습니다.
'Python' 카테고리의 다른 글
| Dask 소개 및 자주 사용하는 함수 (0) | 2022.04.23 |
|---|---|
| 유용한 파이썬 문법(Useful Skill) (0) | 2020.02.24 |
| python으로 동영상 정보 확인하기(feat. PyAV) (0) | 2019.06.10 |
| Python list VS Numpy for matrix multiply (0) | 2019.06.10 |
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
python으로 동영상 정보 확인하기(feat. PyAV)
안녕하세요 coconut입니다. 회사일을 진행하던 중 작업에 동영상 정보를 확인할 일이 생겨서 python으로 동영상을 읽어서 정보를 열람하는 것을 포스팅하게 되었습니다.
우선 동영상을 읽어올 수 있는 여러가지 파이썬 패키지 중에서 저는 PyAV를 선택하여 작업을 해보았습니다.
pip install av설치는 위와 같이 해주면 됩니다.
설치가 안될 시에는 로그를 확인하여 아래와 같이 install dependency를 해결해 준 뒤에 설치를 해줍니다.
case of MacOS
brew install ffmpeg pkg-config
case of Ubuntu >= 18.04 LTS
# General dependencies sudo apt-get install -y python-dev pkg-config
# Library components sudo apt-get install -y \
libavformat-dev libavcodec-dev libavdevice-dev \
libavutil-dev libswscale-dev libswresample-dev libavfilter-dev
case of Ubuntu < 18.04 LTS
sudo apt install \
autoconf \
automake \
build-essential \
cmake \
libass-dev \
libfreetype6-dev \
libjpeg-dev \
libtheora-dev \
libtool \
libvorbis-dev \
libx264-dev \
pkg-config \
wget \
yasm \
zlib1g-dev
wget http://ffmpeg.org/releases/ffmpeg-3.2.tar.bz2 tar -xjf ffmpeg-3.2.tar.bz2 cd ffmpeg-3.2
./configure --disable-static --enable-shared --disable-doc
make
sudo make install
case of windows
https://ffmpeg.zeranoe.com/builds/
를 통하여 설치 후 PyAV를 설치합니다.
설치가 끝나면 제가 테스트 했던 코드를 사용하여 설명을 하겠습니다.
import av # PyAV 임포트
from PIL import Image # Pillow 임포트
# 동영상을 임포트
container = av.open('동영상이름.mp4')
video = container.streams.video[0]
frames = container.decode(video=0)
# 프레임 단위로 동영상에서 이미지 추출
for frame in frames:
frame.to_image().save('frame-%04d.jpg' % frame.index)
# 이미지 하나 추출 뒤 포문 탈출
break
# 동영상 재생시간
time_base = video.time_base
# fps 샘플링 추출
fps = video.average_rate
print(time_base)
print(container.duration)
# 동영상 총 프레임
print(video.frames)
# 초당 프레임 계산
fps_calculate = int(str(fps).split('/')[0]) / int(str(fps).split('/')[1])
print("fps : " + str(fps_calculate))
print("movie seconds : " + str(int(video.frames) / fps_calculate))
# 동영상에서 추출한 이미지의 해상도 계산
im = Image.open('frame-0000.jpg')
width, height = im.size
print("width : " + str(width))
print("height : " + str(height))
코드상의 주석으로 설명이 가능합니다.
fps : Frames Per Second (초당 프레임 개수입니다.) – 보통 30fps
여기까지 간단하게 다뤄 보았습니다. 끝~!
'Python' 카테고리의 다른 글
| 유용한 파이썬 문법(Useful Skill) (0) | 2020.02.24 |
|---|---|
| json to csv by python method call(파이썬으로 json을 csv 변환) (0) | 2019.09.06 |
| Python list VS Numpy for matrix multiply (0) | 2019.06.10 |
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
| Python을 이용한 엑셀 읽기 및 쓰기(xlrd, xlwt) (0) | 2019.06.10 |
Python list VS Numpy for matrix multiply
Hello!! I’m Coconut~
This time, running simple test for matrix multiply with python list and python numpy
Run environment : 800 by 400 X 400 by 800 => 800 by 800
Case1: python list for loop matmul

Case2: numpy ndarray matmul

In this test, Numpy calculation is 180 times faster than python list loop calculation
If you want view this test code, move to below
# -*- coding: utf-8 -*-
import numpy as np
from datetime import datetime
# 일반적인 행렬
normal_matrix1 = [[x for x in range(1, 401)] for e in range(1, 801)]
# numpy 행렬 선언
np_mat1 = np.array(normal_matrix1)
# 행렬2
normal_matrix2 = [[x for x in range(401, 1201)] for e in range(1, 401)]
# numpy 행렬2 선언
np_mat2 = np.array(normal_matrix2)
print("1 : " + str(np_mat1) + str(np_mat1.shape))
print("2 : " + str(np_mat2) + str(np_mat2.shape))
start = datetime.now()
# print(np_test + np2_test)
print("-----------------------------------------------------------------")
mul = np.matmul(np_mat1, np_mat2)
print(str(mul) + " / dimension : " + str(mul.shape))
print("-----------------------------------------------------------------")
end = datetime.now()
# numpy 벡터연산 걸린 시간
print("numpy duration_time : " + str(end - start))
print("-----------------------------------------------------------------")
result = [[0 for x in range(1, 801)] for e in range(1, 801)]
start_normal = datetime.now()
for i in range(len(normal_matrix1)):
for j in range(len(normal_matrix2[0])):
for k in range(len(normal_matrix2)):
result[i][j] += normal_matrix1[i][k] * normal_matrix2[k][j]
end_normal = datetime.now()
# list 연산 걸린 시간
print(str(result))
print("-----------------------------------------------------------------")
print("normal calculation duration_time : " + str(end_normal - start_normal))
print("-----------------------------------------------------------------")
'Python' 카테고리의 다른 글
| json to csv by python method call(파이썬으로 json을 csv 변환) (0) | 2019.09.06 |
|---|---|
| python으로 동영상 정보 확인하기(feat. PyAV) (0) | 2019.06.10 |
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
| Python을 이용한 엑셀 읽기 및 쓰기(xlrd, xlwt) (0) | 2019.06.10 |
| zappa를 이용한 파이썬 서버리스 구현 (0) | 2019.02.14 |
파이썬 크롤링의 기초와 간단한 실행
안녕하세요 코코넛입니다. 이번에는 크롤링 관련 세미나를 진행하면서 정리한 자료를 포스팅하게 되었습니다.
세미나를 진행하면서 사용한 ppt를 포스팅에서 그대로 사용하였습니다.

자 이제 시작합니다!

순서는 간단하게 왜 어떻게 하는지에 대한 이유와 실생활에서 쓰이는 예시,
그리고 전체적인 흐름 및 실행을 다루고 있습니다.

크롤링은 자신의 원하는 정보를 웹페이지에서 가져오는 행위 또는 작업의 의미로 일컬어 집니다.
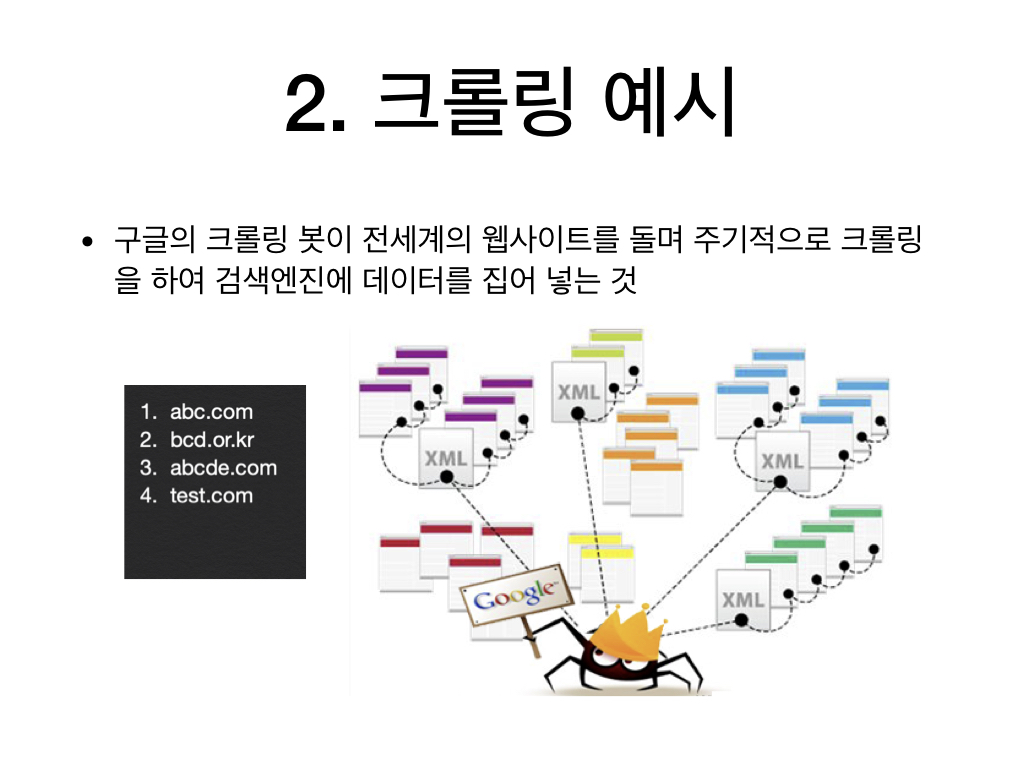
흔한 예로 구글의 검색엔진에 우리가 검색해서 나오는 정보들도 모두 구글의 봇이 크롤링을 하여서 얻어진
정보입니다.

자사의 제품의 정보를 보통은 오픈 마켓에 제공을 하지만 그 외 제품의 정보를 크롤링하여 가져오기도 합니다.
참고로 크롤링한 정보를 상업적으로 사용하려면 정보를 제공하는 측의 허가를 먼저 얻어야 합니다.

API를 통해 얻어오지 못하는 정보도 크롤링으로 얻어올 수 있지요~

크롤링 도구가 있어야 크롤링을 할 수 있겠죠~!
먼저 크롤링할 웹페이지에 접속, 정보선택 후 정보를 가져옵니다. 그 후에 필요한 정보를 파싱하여 사용 혹은 저장!

여기서는 실행할 예시에 셀레늄을 사용하고 있습니다.

가져올 정보의 인덱스를 책갈피에 빗대어 설명을 하였습니다.

실행할 예시입니다.


용어 정리!
실행에 사용한 예제 코드도 첨부하였습니다.
#-*- coding: utf-8 -*-
from selenium import webdriver
from bs4 import BeautifulSoup as bs
import time
search_keyword = "초코파이"
# 크롤링 도구
driver = webdriver.Chrome('/Users/yutaewoong/Downloads/chromedriver')
driver.implicitly_wait(3)
time.sleep(5)
# 오픈마켓 접속
driver.get('http://www.auction.co.kr/')
time.sleep(5)
# 상품 검색
driver.find_element_by_xpath("//*[@class='search_input_keyword']").send_keys(search_keyword)
time.sleep(3)
driver.find_element_by_xpath("//*[@class='search_btn_ok']").click()
time.sleep(5)
# 상품리스트 가져오기
html = driver.page_source
soup = bs(html, 'html.parser')
itemlist = soup.findAll("div", {"class": "section--itemcard"})
time.sleep(10)
# 가져온 상품리스트에서 필요한 상품명, 가격, 상품링크를 출력!!
for item in itemlist:
title = item.find("span", {"class": "text--title"}).text
price = item.find("strong", {"class": "text--price_seller"}).text
link = item.find("span", {"class": "text--itemcard_title ellipsis"}).a['href']
print("상품명 : " + title)
print("가격 : " + price + "원")
print("상품 링크 : " + link)
print("------------------------")
time.sleep(10)
driver.close()여기까지 간단히 소개를 마치겠습니다.
여러분께 도움이 되기를 바라겠습니다~~
'Python' 카테고리의 다른 글
| python으로 동영상 정보 확인하기(feat. PyAV) (0) | 2019.06.10 |
|---|---|
| Python list VS Numpy for matrix multiply (0) | 2019.06.10 |
| Python을 이용한 엑셀 읽기 및 쓰기(xlrd, xlwt) (0) | 2019.06.10 |
| zappa를 이용한 파이썬 서버리스 구현 (0) | 2019.02.14 |
| 간단한 python 이메일 연동하기 (0) | 2019.01.27 |
Python을 이용한 엑셀 읽기 및 쓰기(xlrd, xlwt)
안녕하세요, coconut입니다 이번에는 파이썬을 이용한 엑셀 읽고 쓰기를 알려드리려 합니다.
일단 지금 포스팅에서 쓰이는 라이브러리는 .xls만 지원한다는 점에 유의해 주시기 바랍니다.
.xlsx를 기대하고 찾으신 분은 아쉽지만 다른 블로그를 참고해 주시기 바랍니다.
바로 들어갑니다. 일단 .xls 읽어와 datadict에 저장하기
# -*- coding: utf-8 -*-
import xlrd
# 읽기 라이브러리를 통해 현재 같은 디렉터리상에 있는 test.xls를 불러와 workbook에 할당합니다.
workbook = xlrd.open_workbook('test.xls')
# 워크북에 할당된 엑셀 데이터의 첫번째시트를 불러옵니다.
worksheet = workbook.sheet_by_index(0)
# nrows에 불러온 첫번째 시트의 행수를 불러옵니다.
nrows = worksheet.nrows
# 불러온 데이터를 저장할 딕셔너리를 선언합니다.
datadict = {}
# 행수만큼의 for loop 를 돌려서 행단위로 데이터를 불러와 datadict에 저장합니다.
for row_num in range(nrows):
datadict[row_num] = {}
# field_cnt는 열의 개수입니다. 열갯수는 여러분이 지정하시면 됩니다.
for col in range(field_cnt):
# datadict[row_num]에 열숫자별로 셀데이터를 저장합니다.
datadict[row_num][col] = worksheet.cell_value(row_num, col)
다음은 엑셀 쓰기
workbookw = xlwt.Workbook(encoding='utf-8') # utf-8 인코딩 방식의 workbook 생성
workbookw.default_style.font.height = 20 * 11
worksheetw = workbookw.add_sheet('시트 이름') # 시트 생성
# 2번째 행부터 데이터를 입력합니다.
for row_num in range(nrows):
for col in range(field_cnt):
worksheetw.write(row_num, col, datadict[row_num][col])
# 할당된 데이터셋을 'result.xls'로 저장합니다.
workbookw.save("result.xls")
여기까지 간단한 파이썬 엑셀파일 읽고 쓰기였습니다.
'Python' 카테고리의 다른 글
| Python list VS Numpy for matrix multiply (0) | 2019.06.10 |
|---|---|
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
| zappa를 이용한 파이썬 서버리스 구현 (0) | 2019.02.14 |
| 간단한 python 이메일 연동하기 (0) | 2019.01.27 |
| python socket(tcp, udp) 사용하기 (0) | 2018.12.02 |
zappa를 이용한 파이썬 서버리스 구현
안녕하세요 이번에는 python 코드를 서버없이 실행할 수 있게 해주는 zappa를
사용하는 방법을 소개하겠습니다.
우선 zappa에 관해 간단히 설명을 하겠습니다.
최근들어 aws, azure, gcp 같은 클라우드 플랫폼 서비스에서 서버리스 제품이 출시되고 있는데요,
서버리스란 말 그대로 프로덕트를 서버에서 실행시키지 않고, 자원을 분산시켜 함수는 함수대로 DB는
DB대로 각각 나누어 연동시켜 프로덕트를 동작하게 한다고 할 수 있습니다.
그중에서도 저는 파이썬 패키지로 작성된 서버리스 도구인 zappa를 소개하려고 합니다.
우선 zappa를 설치하는 방법은 각자 자신이 사용하는 파이썬 환경에서
pip install zappa
를 실행하여 주면 됩니다.
현재 zappa는 파이썬 2.7 과 3.6 에서 지원이 되니 참고해 주세요.
간단한 python 모듈을 zappa로 실행시켜 보겠습니다.
myapp.py
# -*- coding: utf-8 -*-
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World! Hello everyone!"
if __name__ == "__main__":
app.run()
myapp.py를 이런식으로 작성한 뒤
zappa init
명령을 내려줍니다.
aws에 로그인하여 IAM에 접속하여 사용자를 추가해 줍니다.
사용자를 추가할 때 aws_access_key_id와 aws_secret_access_key를 얻을 수 있습니다.
그 키를 ~/.aws/credentials 파일이 아래와 같이 저장해 줍니다.
[default] aws_access_key_id=xxxxxxxxxxxxxxxxxxx aws_secret_access_key=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
zappa init를 통해 만들어진 zappa_settings.json 파일을 수정하여 클라우드 서버 환경을 연동시킬 수 있습니다.
예제
{
"dev": {
"app_function": "myapp.app",
"aws_region": "ap-northeast-2",
"profile_name": "default",
"project_name": "test",
"runtime": "python3.6",
"s3_bucket": "test_bucketname"
}
}이제 zappa_settings.json이 존재하는 경로상에서
zappa deploy dev
로 aws 상에서 배포를 하면 끝납니다.
소스를 고치면 다른 명령어로 배포를 할 수 있습니다.
zappa update dev
여기까지 간단한 zappa 사용법이었습니다. 끝!
'Python' 카테고리의 다른 글
| 파이썬 크롤링의 기초와 간단한 실행 (1) | 2019.06.10 |
|---|---|
| Python을 이용한 엑셀 읽기 및 쓰기(xlrd, xlwt) (0) | 2019.06.10 |
| 간단한 python 이메일 연동하기 (0) | 2019.01.27 |
| python socket(tcp, udp) 사용하기 (0) | 2018.12.02 |
| linux 파일 동기화 소스 auto_sync (0) | 2018.09.09 |
간단한 python 이메일 연동하기
안녕하세요 2019년 새해 첫 포스팅은 이메일에 관한 글입니다.
주제는 파이썬으로 이메일 연동하기입니다.
이메일은 크게 smtp(발신) / pop, imap(수신) 프로토콜을 이용해서 전송 및 수신을 합니다.
저는 몇 일간의 삽질을 바탕으로 받고 보내는 함수를 만들었습니다.
이를 바탕으로 여러분도 응용하여 이메일을 손쉽게 제어하시기 바랍니다.
자, 이제 소스를 공개!
import smtplib
import imaplib
import poplib
import email
from email.mime.text import MIMEText
from datetime import datetime
# 보낼 곳과 연동할 이메일 계정
sendto = '받는사람@이메일.com'
user = '보내는사람@이메일.com'
password = "보내는사람 이메일 패스워드"
# 메일을 보내는 함수(smtp)
def send_mail(user, password, sendto, msg_body):
# smtp server
smtpsrv = "smtp.office365.com" # 발신 메일서버 주소
smtpserver = smtplib.SMTP(smtpsrv, 587) # 발신 메일서버 포트
smtpserver.ehlo()
smtpserver.starttls()
smtpserver.login(user, password)
msg = MIMEText(msg_body)
msg['From'] = user
msg['To'] = sendto
msg['Subject'] = "Module Testing email Subject"
smtpserver.sendmail(user, sendto, msg.as_string())
print('done!')
smtpserver.close()
# 메일을 받는 함수(imap4)
def check_mail_imap(user, password):
# imap server
imapsrv = "outlook.office365.com"
imapserver = imaplib.IMAP4_SSL(imapsrv, "993")
imapserver.login(user, password)
imapserver.select('INBOX')
res, unseen_data = imapserver.search(None, '(UNSEEN)')
ids = unseen_data[0]
id_list = ids.split()
latest_email_id = id_list[-10:]
# 메일리스트를 받아서 내용을 파일로 저장하는 함수
for each_mail in latest_email_id:
# fetch the email body (RFC822) for the given ID
result, data = imapserver.fetch(each_mail, "(RFC822)")
msg = email.message_from_bytes(data[0][1])
while msg.is_multipart():
msg = msg.get_payload(0)
content = msg.get_payload(decode=True)
f = open("email_" + str(datetime.now()) + ".html", "wb")
f.write(content)
f.close()
imapserver.close()
imapserver.logout()
# 메일을 받는 함수(pop)
def check_mail_pop(user, password):
# imap server
popsrv = "pop.test.kr"
popserver = poplib.POP3(popsrv, "110")
popserver.user(user)
popserver.pass_(password)
numMsg = len(popserver.list()[1])
for i in range(numMsg):
raw_email = b"\n".join(popserver.retr(i + 1)[1])
msg = email.message_from_bytes(raw_email)
while msg.is_multipart():
msg = msg.get_payload(0)
content = msg.get_payload(decode=True)
f = open("email_" + str(datetime.now()) + ".html", "wb")
f.write(content)
f.close()
popserver.close()
if __name__ == '__main__':
# imap형식 수신 함수
check_mail_imap(user, password)
# pop형식 수신 함수
check_mail_pop(user, password)
# 메일을 보내는 함수 smtp
send_mail(user, password, sendto, "안녕하세요 코코넛이 이메일을 보냅니다.")여기까지 저는 수신한 이메일을 파일로 저장하는 소스를 만들었는데요.
여러분 입맛대로 수정해서 쓰시면 됩니다.
'Python' 카테고리의 다른 글
| Python을 이용한 엑셀 읽기 및 쓰기(xlrd, xlwt) (0) | 2019.06.10 |
|---|---|
| zappa를 이용한 파이썬 서버리스 구현 (0) | 2019.02.14 |
| python socket(tcp, udp) 사용하기 (0) | 2018.12.02 |
| linux 파일 동기화 소스 auto_sync (0) | 2018.09.09 |
| Python패키지 목록 requirements.txt 관리하기 (0) | 2018.08.08 |
python socket(tcp, udp) 사용하기
이번에는 python에서 기본으로 제공하는 socket 모듈을 사용하는 방법을 다루겠습니다.
socket 통신에는 tcp와 udp 두가지가 있습니다.
1. 먼저 tcp – sender
# socket module import!
import socket
# socket create and connection
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(("123.123.123.123", 9999))
# send msg
test_msg = "안녕하세요 상대방님"
sock.send(test_msg)
# recv data
data_size = 512
data = sock.recv(data_size)
# connection close
sock.close()우선 tcp는 위에 모듈을 임포트 한 뒤에 소켓 통신을 할 ip(저는 임의로 123.123.123.123)와 포트를 지정 후에
연결을 합니다.
연결이 성사 되면 test_msg를 send합니다. 그리고 send가 끝나는 동시에 data를 data_size만큼 받아오게 됩니다.
이렇게 tcp를 사용할 수 있습니다. 상황에 맞게 for루프를 돌리거나 수정해서 사용하면 됩니다.
2. tcp – receiver
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
recv_address = ('0.0.0.0', 9999)
sock.bind(recv_address)
sock.listen(1)
conn, addr = s.accept()
# recv and send loop
while 1:
data = conn.recv(BUFFER_SIZE)
# 받고 data를 돌려줌.
conn.send(data)
conn.close()받는 쪽 즉, 서버쪽의 tcp 소스 입니다.
3. 그리고 udp – sender
import socket
# connection create
send_sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
dest = ("127.0.0.1", 9999)
# send to dest
send_sock.sendto(data, dest)
send_sock.close()위에 소스는 출발지 소켓 소스입니다.
4. udp – receiver
import socket
# socket create
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# Bind the socket to the port
recv_address = ('0.0.0.0', 9999)
sock.bind(recv_address)
data_size = 512
data, sender = sock.recvfrom(data_size)
sock.close()위 소스는 목적지 소켓 소스입니다.
끝~!
'Python' 카테고리의 다른 글
| zappa를 이용한 파이썬 서버리스 구현 (0) | 2019.02.14 |
|---|---|
| 간단한 python 이메일 연동하기 (0) | 2019.01.27 |
| linux 파일 동기화 소스 auto_sync (0) | 2018.09.09 |
| Python패키지 목록 requirements.txt 관리하기 (0) | 2018.08.08 |
| 실시간으로 뉴스를 크롤링하여 뉴스 검색엔진 API 만들기 (1) | 2018.08.07 |
