BERT 한국어버전(korquad) training 및 evaluating 해보기
안녕하세요 coconut입니다. 오랜만에 BERT에 관해 포스팅을 하게 되었습니다.
BERT(Bidirectional Encoder Representations from Transformers)는 구글에서 배포한 오픈 소스입니다.
BERT 전에는 NLP 알고리즘으로 높은 퍼포먼스를 자랑하던 ensemble 기법이 있었는데요.
BERT가 Release되고, 많은 분들이 시도를 해보시고 인기도 좋아서 저도 시도를 해보았는데요,
BERT를 한글 기준으로 돌릴 수 있도록 LG CNS에서 데이터를 제공하였는데요, https://korquad.github.io/ 에서
데이터를 확인하실 수 있습니다.
우선 https://github.com/google-research/bert 에 접속하여 bert 오픈소스를 받아 줍니다. 혹은
git clone https://github.com/google-research/bert.git 으로 받으셔도 됩니다.

그리고 fine tuning이 제외된 초기 상태로 진행할 거라면 BERT-Base, Multilingual Cased (New, recommended) 파일도
받아줍니다.
받은 파일을 압축을 풀고 directory 하나를 생성하여 그 안에 넣어줍니다.(저는 pretrained 라고 하였습니다.)
그리고 위의 https://korquad.github.io/ 에 접속하여 Training set 과 Dev set 그리고 evaluating 하기 위해
Evaluation script를 받아 줍니다.
그럼 총 세 개의 파일을 받을 수 있는데요
KorQuAD_v1.0_train.json
KorQuAD_v1.0_dev.json
evaluate-v1.0.py
요 세개를 받으시면 됩니다.
아까 생성한 directory 에 이 파일들도 넣어주셔도 되고, 아니면 그냥 따로 다른 directory 에 넣어주셔도 됩니다.(korquad라고 설정하였습니다.)
이제 tensorflow_gpu 버전이 설치된 서버에서 training을 시켜줍니다.
python run_squad.py –bert_config_file=pretrained/bert_config.json –vocab_file=pretrained/vocab.txt –output_dir=output –do_train=True –train_file=korquad/KorQuAD_v1.0_train.json –do_predict=True –predict_file=korquad/KorQuAD_v1.0_dev.json –do_lower_case=false –num_train_epochs=3.0 –max_seq_length=128 –train_batch_size=32 –init_checkpoint=pretrained/bert_model.ckpt
위의 스크립트대로 실행하였으나 Out Of Memory 이슈로 실행을 하지 못하여 적당히 조절하면서 테스트를 진행하였습니다.
아래는 메모리가 12기가인 GPU 기준으로 max_seq_length와 train_batch_size를 정리하여 놓은 표입니다.

몇 시간 뒤에 training이 끝나면 output 디렉터리에 predictions.json 과 training model 파일들이 생성이 되어 있습니다.
python evaluate-v1.0.py KorQuAD_v1.0_dev.json predictions.json 을 하여 evaluating을 할 수 있습니다.
여기까지 마치겠습니다.
'DeepLearning' 카테고리의 다른 글
| 간단하게 보는 CPU와 GPU의 연산 차이 (0) | 2018.03.29 |
|---|---|
| Python 딥러닝 관련 간단한 활성화 함수 (0) | 2018.02.20 |
간단하게 보는 CPU와 GPU의 연산 차이
이번에는 요근래 하드웨어들의 스펙이 급등하면서 생기는 현상 중 병렬 프로그래밍의 본좌인 GPU와
그에 비교되는 CPU의 차이를 예전에 만들었던 PPT를 참고하여 글을 써보았습니다.
일단 기본적인 차이점을 보자면,
- CPU와는 달리 GPU는 코어가 아주 많다.
- CPU는 복잡한 계산을 빠르게 할 수 있지만 모두 직렬로 처리한다.
- GPU는 간단한 계산을 빠르게 할 수 있고, 많은 연산을 병렬로 동시에 할 수 있다.
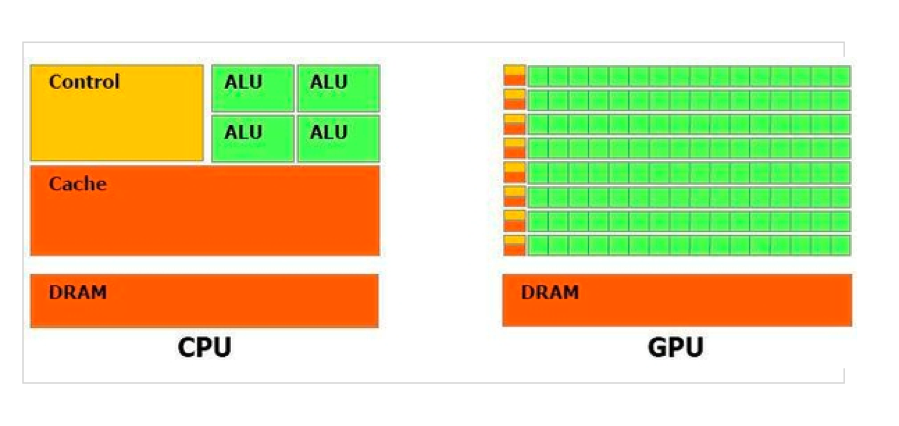
그림으로 연산하는 과정을 대략적으로 표현해 보면,

이런식입니다.
CPU와 GPU 장단점을 보면,
- CPU
- 복잡한 계산을 코어 갯수 만큼씩 처리하게 된다.
- 예로 복잡한 팩토리얼 계산식을 2개 계산해야 한다고 했을 때 CPU로 계산을 해주면 빨리할 수 있다.
- 단점 – 간단하고 많은 계산식은 오래걸린다
2. GPU
- 간단한 아주 많은 계산식을 동시에 빠르게 처리할 수 있다.
- 예로 1000개의 덧셈식을 한번에 병렬로 처리가 가능하다.
- 단점 – 초기에 알고리즘을 하드웨어에 병렬로 부여해 주어야 하고, 복잡한 식을 입력하면 도리어 CPU 연산 속도보다 느려질 수 있다.
이정도 입니다.
여기까지 간단하게 본 CPU와 GPU 연산의 차이점이었습니다.
틀린 부분이 있으면 답글 달아주시면 수정하겠습니다^^
'DeepLearning' 카테고리의 다른 글
| BERT 한국어버전(korquad) training 및 evaluating 해보기 (0) | 2019.09.04 |
|---|---|
| Python 딥러닝 관련 간단한 활성화 함수 (0) | 2018.02.20 |
Python 딥러닝 관련 간단한 활성화 함수
딥러닝 공부를 하는 중이나 복습 차 python코드로 된 활성화 함수 몇가지를 올려봅니다.
여기서 활용하는 함수들의 출처는 – 밑바닥부터 시작하는 딥러닝 – 에서 참고하였습니다.
일단 신경망의 기초가 되는 퍼셉트론에서는 활성화 함수로 계단 함수를 이용한다라 할 수 있습니다.
python으로 구현하는 간단한 계단함수 코드는
def step_function(x):
if x > 0:
return 1
else:
return 0가 되겠습니다.
x가 0을 기준으로 0과 1로 결과값이 나눠집니다.
이 코드를 numpy를 사용하여 더 편하게 사용하려면
import numpy as np
def step_function(x):
return np.array(x > 0, dtype=np.int)로 사용하시면 되겠습니다.
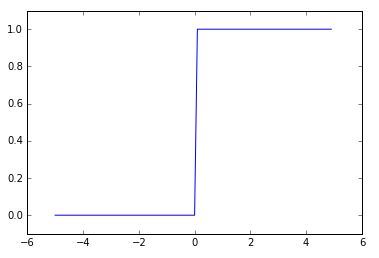
결과값이 true 또는 false로 분기되는 것을 dtype=np.int를 통해 정수형으로 형변환을 시켜주는 원리입니다.
여기까지는 계단함수를 보았습니다.
다음은 시그모이드 함수 구현입니다.
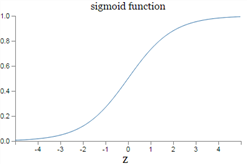
시그모이드의 공식은 아래와 같습니다.

이것을 numpy를 통해 쉽게 코드로 구현하면
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))그래프는 아래와 같이 나옵니다.
마지막으로 (ReLU)렐루 함수를 보겠습니다.
렐루 함수는 0이하이면 0을 출력, 0을 넘으면 그대로의 값을 출력하는 함수입니다.
렐루 함수는 파이썬 코드로 상당히 간결하게 구현이 가능합니다.
import numpy as np
def relu(x):
return np.maximum(0, x)위와 같이 0과 값중에 최대값을 출력하면 렐루 함수가 됩니다.

여기까지 간단한 Python코드로 구현해보는 활성화 함수 세가지를 보았습니다.
'DeepLearning' 카테고리의 다른 글
| BERT 한국어버전(korquad) training 및 evaluating 해보기 (0) | 2019.09.04 |
|---|---|
| 간단하게 보는 CPU와 GPU의 연산 차이 (0) | 2018.03.29 |
